CNN-Based Peak Fitting in Synthetic XRD-CT Datasets
📝 Introduction
In this notebook, we investigate a new self-supervised deep learning approach for peak fitting in synthetic XRD-CT datasets, and compare it to a conventional parameter-based fitting workflow. Both approaches are applied to a phantom dataset generated using the nDTomo package, simulating realistic peak shapes and background contributions under Poisson noise.
Peak fitting remains a critical step in XRD-CT analysis, enabling the extraction of quantitative parameters such as phase content, strain, and crystallite size. However, traditional voxel-by-voxel fitting methods can be slow, sensitive to noise, and difficult to scale. Here, we test whether a CNN trained directly on downsampled spectra can learn to infer accurate and denoised peak parameter maps.
🎯 Objectives
By the end of this notebook, you will:
Generate a synthetic 3D XRD-CT dataset with spatially varying Gaussian peaks and linear background
Add realistic Poisson noise to simulate photon-limited experiments
Fit the data using two approaches:
Conventional parameter map-based fitting
PeakFitCNN: a self-supervised CNN that infers peak parameters from downsampled input
Evaluate and compare the accuracy and noise robustness of both methods
🤖 What is PeakFitCNN?
PeakFitCNN is a self-supervised convolutional neural network designed to learn peak parameters from hyperspectral XRD-CT data without needing ground truth labels. It works by:
Receiving a 4× downsampled hyperspectral input volume
Predicting full-resolution parameter maps (amplitude, position, width, background slope and intercept)
Reconstructing the spectra using a differentiable peak model
Optimizing only through the reconstruction error
This approach naturally combines denoising, super-resolution, and peak decomposition, while avoiding the instability of pixel-wise nonlinear curve fitting.
📦 Dataset
We will use a synthetic dataset constructed as follows:
Each voxel contains a single Gaussian peak with a linear background
The five peak parameters vary smoothly across the field of view
The diffraction axis is sampled over:
where \(q\) represents the diffraction domain (e.g., \(2\theta\)).
Poisson noise is added to approximate photon-counting uncertainty, mimicking experimental conditions.
We now begin by importing the required modules and generating the simulated dataset.
🏗️ Generate Synthetic Spatial Maps
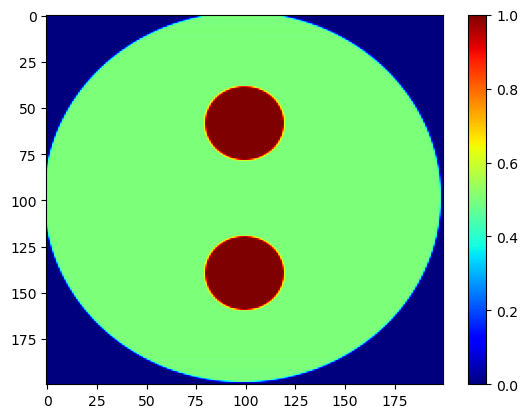
We begin by generating five synthetic 2D spatial images using the nDTomophantom_2D() function. Each image (im1 to im5) will later be used to define a different peak or background parameter (e.g., peak position, width, amplitude, background slope/intercept) across the field of view.
These phantoms serve as parameter maps with smoothly varying features, simulating different chemical or structural domains in a realistic XRD-CT sample.
We also normalize im5 so that it scales between 0 and 1, which is useful for defining background offset values. Finally, the spatial maps are visualized using showim() to verify the underlying structures.
[1]:
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
from nDTomo.sim.phantoms import load_example_patterns, nDTomophantom_2D, nDTomophantom_3D
from nDTomo.methods.plots import showspectra, showim
# Create 2D spatial images for the five components
npix = 200
im1, im2, im3, im4, im5 = nDTomophantom_2D(npix, nim='Multiple')
iml = [im1, im2, im3, im4, im5]
im5 = im5/np.max(im5)
%matplotlib inline
# Optionally display spatial maps
showim(im1, 2)
showim(im2, 3)
showim(im3, 4)
showim(im4, 5)
showim(im5, 6)
c:\Users\anton\anaconda3\envs\ndtomo\lib\site-packages\h5py\__init__.py:36: UserWarning: h5py is running against HDF5 1.12.2 when it was built against 1.12.1, this may cause problems
_warn(("h5py is running against HDF5 {0} when it was built against {1}, "
c:\Users\anton\anaconda3\envs\ndtomo\lib\site-packages\paramiko\pkey.py:82: CryptographyDeprecationWarning: TripleDES has been moved to cryptography.hazmat.decrepit.ciphers.algorithms.TripleDES and will be removed from this module in 48.0.0.
"cipher": algorithms.TripleDES,
c:\Users\anton\anaconda3\envs\ndtomo\lib\site-packages\paramiko\transport.py:219: CryptographyDeprecationWarning: Blowfish has been moved to cryptography.hazmat.decrepit.ciphers.algorithms.Blowfish and will be removed from this module in 45.0.0.
"class": algorithms.Blowfish,
c:\Users\anton\anaconda3\envs\ndtomo\lib\site-packages\paramiko\transport.py:243: CryptographyDeprecationWarning: TripleDES has been moved to cryptography.hazmat.decrepit.ciphers.algorithms.TripleDES and will be removed from this module in 48.0.0.
"class": algorithms.TripleDES,
c:\Users\anton\anaconda3\envs\ndtomo\lib\site-packages\xdesign\geometry\area.py:789: UserWarning: Didn't check that Mesh contains Circle.
warnings.warn("Didn't check that Mesh contains Circle.")
🧪 Simulate Hyperspectral Volume with Spatially Varying Peak Parameters
We now define the analytical peak model used to generate our synthetic dataset. Each voxel in the volume will contain a spectrum consisting of a single Gaussian peak with a linear background.
Two functions are defined:
gaussian(x, A, mu, sigma)– generates a peak given amplitude, center, and widthlinear_background(x, slope, intercept)– models a linear baseline across the diffraction axis
We then:
Define the diffraction axis
x, sampled between 0 and 5 with a step size of 0.1Specify the valid parameter ranges for all five quantities:
Peak amplitude (A): varies with
im2 + im5Peak position (μ): varies with
im2Peak width (σ): varies with
im3Background slope: varies with
im4Background intercept: varies with
im5
The resulting 2D hyperspectral image vol is populated voxel-by-voxel, only in regions with non-negligible peak amplitude (mask_tmp > 0).
We then pad the hyperspectral image spatially by 20 pixels on each side to ensure compatibility with CNN architectures that may expect padding or stride-sensitive dimensions.
Finally, we simulate Poisson noise using the addpnoise3D() function, which mimics photon-counting statistics typically observed in synchrotron X-ray imaging. The noise level is controlled by a ct value (e.g. 100 = moderate photon count). The resulting noisy synthetic dataset will be used for both conventional and CNN-based fitting.
[2]:
def linear_background(x, slope, intercept):
return slope*x + intercept
def gaussian(x, A, mu, sigma):
return A * np.exp(-(x - mu)**2 / (2*sigma**2))
# Define the x axis
# x = np.arange(0, 5, 0.025)
# x = np.arange(0, 5, 0.075)
x = np.arange(0, 5, 0.1)
# Define the min/max for the various parameters
peak1_mu_min = 2
peak1_mu_max = 3
peak1_sigma_min = 0.2
peak1_sigma_max = 0.4
peak1_A_min = 0
peak1_A_max = 1.25
bkg_slope_min = 0.0
bkg_slope_max = 0.025
bkg_intercept_min = 0.05
bkg_intercept_max = 0.25
im6 = im2 + im5
im6 = im6 / np.max(im6)
peak_area = peak1_A_min + im6*(peak1_A_max - peak1_A_min)
peak_position = peak1_mu_min + im2*(peak1_mu_max - peak1_mu_min)
peak_fwhm = peak1_sigma_min + im3*(peak1_sigma_max - peak1_sigma_min)
peak_slope = bkg_slope_min + im4*(bkg_slope_max - bkg_slope_min)
peak_intercept = bkg_intercept_min + im5*(bkg_intercept_max - bkg_intercept_min)
vol = np.zeros((im1.shape[0], im1.shape[1], len(x)), dtype = 'float32')
mask_tmp = np.copy(peak_area)
mask_tmp[mask_tmp<0.0001] = 0
mask_tmp[mask_tmp>0] = 1
for ii in tqdm(range(im1.shape[0])):
for jj in range(im1.shape[1]):
if mask_tmp[ii,jj] > 0:
vol[ii,jj,:] = gaussian(x, A=peak_area[ii,jj], mu=peak_position[ii,jj], sigma=peak_fwhm[ii,jj]) + \
linear_background(x, slope=peak_slope[ii,jj], intercept=peak_intercept[ii,jj])
extra = 20
vol = np.concatenate((np.zeros((vol.shape[0], extra, len(x)), dtype = 'float32'), vol, np.zeros((vol.shape[0], extra, len(x)), dtype = 'float32')), axis=1)
vol = np.concatenate((np.zeros((extra, vol.shape[1], len(x)), dtype = 'float32'), vol, np.zeros((extra, vol.shape[1], len(x)), dtype = 'float32')), axis=0)
print(vol.shape, np.max(vol))
def addpnoise3D(vol, ct):
'''
Adds Poisson noise to a 3D hyperspectral volume (H x W x Bands),
noise is added per pixel-spectrum (i.e., per (i,j,:)).
Parameters
----------
vol : ndarray
3D hyperspectral image (H x W x Bands), must be non-negative.
ct : float
Scaling constant to simulate photon counts.
'''
vol = vol.copy()
mi = np.min(vol)
if mi < 0:
vol = vol - mi + np.finfo(np.float32).eps
elif mi == 0:
vol = vol + np.finfo(np.float32).eps
# Apply Poisson noise per pixel-spectrum
noisy = np.random.poisson(vol * ct) / ct
return noisy
# vol = vol + 0.001*np.random.rand(vol.shape[0], vol.shape[1], vol.shape[2])
# # vol = addpnoise3D(vol, ct=1000)
vol = addpnoise3D(vol, ct=100)
vol[vol<0] = 0
100%|██████████| 200/200 [00:00<00:00, 529.01it/s]
(240, 240, 50) 1.5
We can now interactively explore the spectral content of this volume using the chemimexplorer
[3]:
from nDTomo.methods.hyperexpl import chemimexplorer
%matplotlib widget
# Create an instance of the GUI
gui = chemimexplorer(vol)
🎯 Patch Sampling Strategy for CNN Training
To train the PeakFitCNN model efficiently, we operate on smaller image patches rather than the full hyperspectral volume. This section defines a patch-based sampling strategy that allows randomized, GPU-efficient access to valid (non-zero) regions of the volume.
Key steps include:
Patch and sampling parameters:
patch_size = 32: the spatial size of each square patchnum_patches = 16: number of patches drawn per iteration (i.e., batch size)num_iterations = 100: total training steps per epoch
Valid mask generation:
A binary mask is computed from the sum over spectral channels to identify meaningful (non-zero) regions.
Padding is added to the volume and mask to ensure valid patch extraction near image borders.
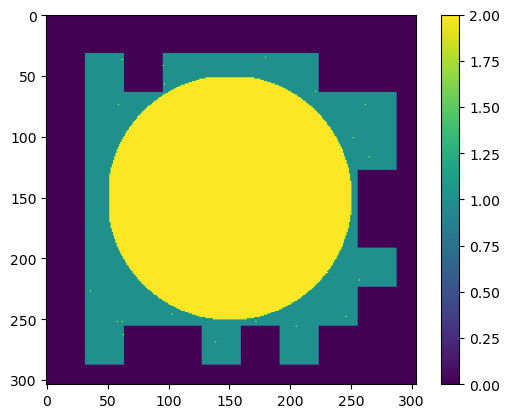
Sampling diagnostics:
We estimate the percentage of pixels probed per epoch, based on patch size and number.
We compute the number of iterations required to probe the entire image once.
Patch index selection:
Valid patch indices are extracted using
filter_patch_indices()to avoid sampling background-only regions.These indices are used to initialize a patch-based coverage
counterwhich tracks how often each pixel is sampled.
Visualization:
We visualize both the binary mask and the patch coverage map, helping verify that the sampling scheme is balanced and covers all important regions.
This patch sampling setup enables training with limited memory while ensuring statistical coverage of the whole sample over multiple iterations.
[ ]:
import torch, time
import torch.nn.functional as F
from torch import nn
from nDTomo.pytorch.utils_torch import calc_patches_indices, denormalize, filter_patch_indices, update_counter, initialize_counter, calc_patches_indices
%matplotlib inline
num_iterations = 100
distribution_type = 'uniform'
std_dev = int(vol.shape[0] / 1)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
patch_size = 32
num_patches = 16
num_patches_total = 16
mask = np.copy(np.sum(vol,axis=2))
mask[mask>0] = 1
mask = np.concatenate((np.zeros((patch_size, mask.shape[1]), dtype='float32'), mask, np.zeros((patch_size, mask.shape[1]), dtype='float32')), axis = 0)
mask = np.concatenate((np.zeros((mask.shape[0], patch_size), dtype='float32'), mask, np.zeros((mask.shape[0], patch_size), dtype='float32')), axis = 1)
volp = np.copy(vol)
volp = np.concatenate((np.zeros((patch_size, volp.shape[1], volp.shape[2]), dtype='float32'), volp, np.zeros((patch_size, volp.shape[1], volp.shape[2]), dtype='float32')), axis = 0)
volp = np.concatenate((np.zeros((volp.shape[0], patch_size, volp.shape[2]), dtype='float32'), volp, np.zeros((volp.shape[0], patch_size, volp.shape[2]), dtype='float32')), axis = 1)
rows, cols = volp.shape[0], volp.shape[1] # Size of the matrix
print(volp.shape, vol.shape, mask.shape)
plt.figure(1);plt.clf()
plt.imshow(mask)
plt.colorbar()
plt.show()
npix = np.sum(mask)
pcr_probed = 100* (patch_size*patch_size*num_patches)/npix
print(f"Percentage of pixels probed during one epoch: {pcr_probed}")
niters_required = int(np.ceil(100/pcr_probed))
print(f"Number of iterations required to probe full image: {niters_required}")
mask_t = torch.tensor(mask, dtype=torch.bool, device=device)
indices = filter_patch_indices(torch.tensor(mask), patch_size)
print('The number of patches is ', len(indices))
print('The number of iterations (batches) required to probe the whole image is ', int(len(indices)/num_patches) )
counter = initialize_counter(rows, cols)
patch_dimensions = (patch_size, patch_size)
update_counter(counter, indices, patch_dimensions)
print(counter.max())
counter = counter.numpy()
plt.figure(2);plt.clf()
plt.imshow(counter + mask)
plt.colorbar()
plt.show()
(304, 304, 50) (240, 240, 50) (304, 304)
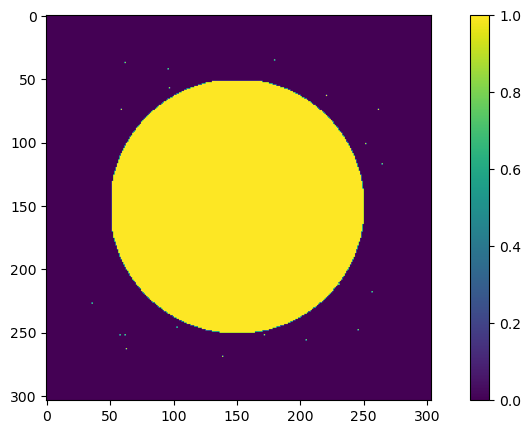
Percentage of pixels probed during one epoch: 51.63893091275845
Number of iterations required to probe full image: 2
The number of patches is 53
The number of iterations (batches) required to probe the whole image is 3
tensor(1.)
🧠 Define PeakFitCNN Architecture and Initial Parameter Model
This section defines the neural network components used in the PeakFitCNN pipeline.
📐 PeakFitCNN Class
The PeakFitCNN class implements a self-supervised upsampling CNN that takes a spatially downsampled hyperspectral input (e.g., 4× smaller) and predicts full-resolution maps of peak parameters. It supports configurable normalization (instance, batch, or layer norm), bilinear upsampling, and optional final activation (e.g., ReLU or Sigmoid).
The input is typically the downscaled hyperspectral imaging data or a low-resolution estimate or feature map.
The output is a stack of parameter maps (e.g., amplitude, center, width, background).
The network upsamples via two stages (2× + 2× for a total 4×).
🧩 PrmCNN2D Class
The PrmCNN2D class provides a modular structure for representing the initial parameter maps:
If
prms_layer=True, it holds a set of trainable parameter tensors, e.g. initialized to zeros or random values.If
cnn_layer=True, a CNN is applied to either:the initialized parameters, or
a provided input volume.
This module can operate in three modes:
Parameter map only (
prms_layer=True,cnn_layer=False) — conventional approach.CNN only (
prms_layer=False,cnn_layer=True) — fully learned from input.Combined (
prms_layer=True,cnn_layer=True) — trainable initial maps refined via CNN layers.
🔢 Configuration and Parameter Count
We define:
A single Gaussian peak per spectrum (
num_peaks = 1)3 peak parameters (area, position, width)
2 background parameters (slope, intercept)
total_params = 5
We instantiate the PrmCNN2D model in parameter-map-only mode, initialized to zero. This setup corresponds to the conventional voxel-wise fitting approach, where each parameter is independently stored as a learnable 2D map.
The total number of trainable parameters is printed for comparison with the full resolution grid size.
[ ]:
class PeakFitCNN(nn.Module):
def __init__(self, nch_in=1, nch_out=1, nfilts=32, upscale_factor = 4,
norm_type='instance', activation='Linear', padding='same', npix=None):
super(PeakFitCNN, self).__init__()
self.npix = npix
self.upscale_factor = upscale_factor
# Initial feature extraction
self.input = nn.Conv2d(nch_in, nfilts, kernel_size=3, stride=1, padding=padding, bias=True)
layers = []
layers.append(nn.Upsample(scale_factor=2, mode="bilinear", align_corners=False))
layers.append(nn.Conv2d(nfilts, nfilts, kernel_size=3, stride=1, padding=padding, bias=True))
# Add normalization based on norm_type
if norm_type == "instance":
layers.append(nn.InstanceNorm2d(nfilts, affine=True))
elif norm_type == "batch":
layers.append(nn.BatchNorm2d(nfilts))
elif norm_type == "layer":
layers.append(nn.LayerNorm([nfilts, 2*self.npix, 2*self.npix]))
# Add activation function
layers.append(nn.ReLU(inplace=True))
self.upsample1 = nn.Sequential(*layers)
if self.upscale_factor == 4:
layers = []
layers.append(nn.Upsample(scale_factor=2, mode="bilinear", align_corners=False))
layers.append(nn.Conv2d(nfilts, nfilts, kernel_size=3, stride=1, padding=padding, bias=True))
# Add normalization based on norm_type
if norm_type == "instance":
layers.append(nn.InstanceNorm2d(nfilts, affine=True))
elif norm_type == "batch":
layers.append(nn.BatchNorm2d(nfilts))
elif norm_type == "layer":
layers.append(nn.LayerNorm([nfilts, 4*self.npix, 4*self.npix]))
# Add activation function
layers.append(nn.ReLU(inplace=True))
self.upsample2 = nn.Sequential(*layers)
# Final output layer
self.xrdct = nn.Conv2d(nfilts, nch_out, kernel_size=3, stride=1, padding=padding, bias=True)
# Final activation
self.final_activation = None
if activation == "ReLU":
self.final_activation = nn.ReLU()
elif activation == "Sigmoid":
self.final_activation = nn.Sigmoid()
elif activation == "LeakyReLU":
self.final_activation = nn.LeakyReLU(0.2, inplace=True)
def forward(self, x): # Feature maps from autoencoder2D are passed
x = self.input(x)
# Upsampling 1
x = self.upsample1(x)
if self.upscale_factor == 4:
# Upsampling 2
x = self.upsample2(x)
# Output layer
x = self.xrdct(x)
if self.final_activation is not None:
x = self.final_activation(x)
return x
class PrmCNN2D(nn.Module):
def __init__(self, npix, nch_in=1, nch_out=1, nfilts=32, nlayers=4, norm_type='layer',
prms_layer=True, cnn_layer=True, tensor_vals = 'random', tensor_initial = None,
padding='same'):
super(PrmCNN2D, self).__init__()
self.npix = npix
self.prms_layer = prms_layer
self.cnn_layer = cnn_layer
if self.prms_layer:
if tensor_vals == 'random':
self.initial_tensor = nn.Parameter(2*torch.randn(1, nch_in, npix, npix)-1)
elif tensor_vals == 'zeros':
self.initial_tensor = nn.Parameter(torch.zeros(1, nch_in, npix, npix))
elif tensor_vals == 'ones':
self.initial_tensor = nn.Parameter(torch.ones(1, nch_in, npix, npix))
elif tensor_vals == 'mean':
self.initial_tensor = nn.Parameter(0.5*torch.ones(1, nch_in, npix, npix))
elif tensor_vals == 'random_positive':
self.initial_tensor = nn.Parameter(torch.randn(1, nch_in, npix, npix))
elif tensor_vals == 'custom':
try:
self.initial_tensor = nn.Parameter(tensor_initial)
except:
print('Custom tensor not provided. Using random tensor instead')
self.initial_tensor = nn.Parameter(torch.randn(1, nch_in, npix, npix))
if self.cnn_layer:
layers = []
layers.append(nn.Conv2d(nch_in, nfilts, kernel_size=3, stride=1, padding=padding)) # 'same' padding in PyTorch is usually done by manually specifying the padding
if norm_type=='layer':
if padding=='valid':
layers.append(nn.LayerNorm([nfilts, self.npix -2, self.npix -2]))
else:
layers.append(nn.LayerNorm([nfilts, self.npix, self.npix]))
elif norm_type=='instance':
layers.append(nn.InstanceNorm2d(nfilts, affine = True))
elif norm_type=='batchnorm':
layers.append(nn.BatchNorm2d(nfilts))
layers.append(nn.ReLU())
for layer in range(nlayers):
layers.append(nn.Conv2d(nfilts, nfilts, kernel_size=3, stride=1, padding=padding))
if norm_type=='layer':
if padding=='valid':
layers.append(nn.LayerNorm([nfilts, self.npix -2*(layer + 2), self.npix -2*(layer + 2)]))
else:
layers.append(nn.LayerNorm([nfilts, self.npix, self.npix]))
elif norm_type=='instance':
layers.append(nn.InstanceNorm2d(nfilts, affine = True))
elif norm_type=='batchnorm':
layers.append(nn.BatchNorm2d(nfilts))
layers.append(nn.ReLU())
layers.append(nn.Conv2d(nfilts, nch_out, kernel_size=3, stride=1, padding=padding))
layers.append(nn.Sigmoid())
self.cnn2d = nn.Sequential(*layers)
def forward(self, x):
if self.prms_layer and self.cnn_layer:
out = self.cnn2d(torch.sigmoid(self.initial_tensor))
elif self.cnn_layer and not self.prms_layer:
out = self.cnn2d(x)
elif self.prms_layer and not self.cnn_layer:
out = torch.sigmoid(self.initial_tensor)
return out
npix_x = volp.shape[0]
npix_y = volp.shape[1]
xv = torch.tensor(x, dtype=torch.float32, device=device)
### Single peak
peak_definitions = [(1, 1.0, 4.0)]
num_peaks = len(peak_definitions)
num_params_per_peak = 3 # Area, Position, FWHM
background_params = 2 # Slope, Intercept
total_params = num_peaks * num_params_per_peak + background_params
npix = volp.shape[0]
nch_in = total_params
nch_out = total_params
nfilts = 2*total_params # 2*total_params is pretty good when using norm layer
norm_type='layer'
activation='Sigmoid'
downsampling = 8
model = PrmCNN2D(npix, nch_in=nch_in, nch_out=nch_out, nfilts=nfilts, nlayers=1, norm_type='None', prms_layer=True, cnn_layer=False, tensor_vals = 'zeros').to(device)
model_prms = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Total number of parameters: {model_prms}")
print("Conventional number of parameters:", npix*npix*total_params)
Total number of parameters: 462080
Conventional number of parameters: 462080
🧪 Train PeakFitCNN in a Self-Supervised Manner
We now train the PeakFitCNN model using a self-supervised learning strategy based on physical reconstruction of the spectra. The CNN is optimized to predict normalized peak parameter maps, from which we reconstruct the full hyperspectral volume and compare it directly to the observed data (volp).
🧱 Model Components
Gaussian model: The
gaussian()function defines the parametric form of the peak used for spectral reconstruction.Normalization bounds: We define
param_minandparam_maxdictionaries that set the physical limits for each parameter type (Area, Position, FWHM, Slope, Intercept). These are used to scale network outputs to valid physical ranges.Loss function: Mean Absolute Error (L1 loss) is used as the reconstruction loss. Additional metrics (MSE, RMSE) are also tracked for monitoring.
Input image: We create a single-channel static image from the sum of all spectral channels, normalized and reshaped appropriately for the CNN input.
🔁 Training Loop
The model is trained over multiple epochs using the following loop:
The CNN produces a set of normalized parameter maps (
yc) from the static image input.These maps are locally filtered and then clamped using a ±20% soft constraint (
prf) to stabilize training.Parameters are denormalized and used to reconstruct each spectrum voxel-by-voxel:
Gaussian peaks are added for each voxel using predicted amplitude, position, and width.
Linear background is then added using predicted slope and intercept.
The reconstructed spectra are compared to the ground truth data (
volp) for randomly sampled patches.Loss is computed using RMSE and gradients are backpropagated to update model parameters.
A learning rate scheduler reduces the step size upon plateauing, and early stopping is triggered if the minimum learning rate is reached.
🕒 Training Time & Convergence
This block tracks:
Total training time
Number of epochs until convergence
Final MAE, MSE, RMSE
A loss log (
logloss) for plotting learning curves later
This setup enables self-supervised training of peak parameters without any labelled supervision — the only objective is to minimize the difference between the observed and reconstructed spectra.
[6]:
def gaussian(x, area, position, fwhm):
"""Gaussian peak shape."""
return area * torch.exp(-(x - position)**2 / (2 * fwhm**2))
MAE = torch.nn.L1Loss()
### Single peak ###
param_min = {
'Area': torch.zeros(num_peaks, dtype=torch.float32).to(device),
'Position': torch.tensor([peak[1] for peak in peak_definitions], dtype=torch.float32).to(device),
'FWHM': torch.zeros(num_peaks, dtype=torch.float32).to(device) + 0.1,
'Fraction': torch.zeros(num_peaks, dtype=torch.float32).to(device),
'Slope': torch.zeros(1, dtype=torch.float32).to(device),
'Intercept': torch.zeros(1, dtype=torch.float32).to(device),
}
param_max = {
'Area': torch.zeros(num_peaks, dtype=torch.float32).to(device) + 2,
'Position': torch.tensor([peak[2] for peak in peak_definitions], dtype=torch.float32).to(device),
'FWHM': torch.zeros(num_peaks, dtype=torch.float32).to(device) + 0.5,
'Fraction': torch.zeros(num_peaks, dtype=torch.float32).to(device) + 1,
'Slope': torch.zeros(1, dtype=torch.float32).to(device) + 0.2,
'Intercept': torch.zeros(1, dtype=torch.float32).to(device) + 0.5,
}
nch = volp.shape[2]
learning_rate = 0.001
epochs = 10000
min_lr = 1E-5
im_static = np.sum(volp, axis=2)
im_static = im_static/np.max(im_static)
im_static = np.reshape(im_static, (1, 1, volp.shape[1], volp.shape[1]))
im_static = torch.tensor(im_static, dtype=torch.float32, device=device)
yobs = np.transpose(volp, (2,1,0))
yobs = torch.tensor(yobs, dtype=torch.float32, device=device)
yobs = torch.reshape(yobs, (1, yobs.shape[0], yobs.shape[1], yobs.shape[2]))
yobs = torch.transpose(yobs, 3, 2)
with torch.no_grad():
yprms = model(im_static)
yprms = F.interpolate(yprms, scale_factor=1/4, mode='bilinear', align_corners=False)
epochs = 50000
patience = 100 #250
min_lr = 1E-5
learning_rate = 0.1
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
prf = 0.2
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, patience=patience, factor=0.5, min_lr=min_lr)
num_patches = 16
new_indices = np.array(indices)
total_indices = len(indices)
num_batches = (total_indices + num_patches - 1) // num_patches
print(num_batches)
start = time.time()
logloss = []
for epoch in tqdm(range(epochs)):
loss_acc = 0
for batch_index in range(num_batches):
start_index = batch_index * num_patches
end_index = min(start_index + num_patches, total_indices)
batch_indices = new_indices[start_index:end_index]
yc = model(im_static)
filtered = nn.AvgPool2d(kernel_size=3, stride=1, padding=1)(yc)
lower_bound = filtered * (1 - prf)
upper_bound = filtered * (1 + prf)
yc = torch.clamp(yc, min=lower_bound, max=upper_bound)
yc = calc_patches_indices(batch_indices, yc, patch_size, use_middle=False)
y = torch.zeros((patch_size*patch_size*len(batch_indices), len(xv)), dtype=torch.float32).to(device)
for i in range(num_peaks):
area = denormalize(yc[:, i * 3, :, :], 'Area', param_min, param_max, i)
position = denormalize(yc[:, i * 3 + 1, :, :], 'Position', param_min, param_max, i)
fwhm = denormalize(yc[:, i * 3 + 2, :, :], 'FWHM', param_min, param_max, i)
area = torch.transpose(torch.reshape(area, (area.shape[0], area.shape[1]*area.shape[2])), 1, 0)
position = torch.transpose(torch.reshape(position, (position.shape[0], position.shape[1]*position.shape[2])), 1, 0)
fwhm = torch.transpose(torch.reshape(fwhm, (fwhm.shape[0], fwhm.shape[1]*fwhm.shape[2])), 1, 0)
area = torch.reshape(area, (area.shape[0]*area.shape[1], 1))
position = torch.reshape(position, (area.shape[0]*area.shape[1], 1))
fwhm = torch.reshape(fwhm, (area.shape[0]*area.shape[1], 1))
y += gaussian(xv.unsqueeze(0), area, position, fwhm)
slope = denormalize(yc[:, -2, :, :], 'Slope', param_min, param_max, )
intercept = denormalize(yc[:, -1, :, :], 'Intercept', param_min, param_max, )
slope = torch.transpose(torch.reshape(slope, (slope.shape[0], slope.shape[1]*slope.shape[2])), 1, 0)
intercept = torch.transpose(torch.reshape(intercept, (intercept.shape[0], intercept.shape[1]*intercept.shape[2])), 1, 0)
slope = torch.reshape(slope, (slope.shape[0]*slope.shape[1], 1))
intercept = torch.reshape(intercept, (intercept.shape[0]*intercept.shape[1], 1))
y += slope * xv + intercept
patches = calc_patches_indices(batch_indices, yobs, patch_size, use_middle=False)
patches = torch.reshape(patches, (patches.shape[0],patches.shape[1],patches.shape[2]*patches.shape[3]))
patches = torch.transpose(patches, 1, 2)
patches = torch.transpose(patches, 1, 0)
y = torch.reshape(y, (patches.shape[0], patches.shape[1], nch))
loss_mae = MAE(patches, y)
loss_mse = torch.mean((patches - y) ** 2)
loss_rmse = torch.sqrt(torch.mean((patches - y) ** 2))
loss_acc = loss_acc + loss_rmse
loss = loss_rmse
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_acc = loss_acc/num_batches
logloss.append(loss_acc.cpu().detach().numpy())
scheduler.step(logloss[-1])
if epoch % (int(patience/2)) == 0:
print('MAE = ', loss_mae, 'MSE = ', loss_mse,'RMSE = ', loss_rmse)
print('Accumulated Loss = ', logloss[-1])
if optimizer.param_groups[0]['lr'] == scheduler.min_lrs[0]:
print("Minimum learning rate reached, stopping the optimization")
print(epoch)
break
total_time = time.time() - start
print(epoch, loss_mae, loss_mse, loss_rmse, logloss[-1])
print(total_time)
4
0%| | 3/50000 [00:00<32:39, 25.52it/s]
MAE = tensor(0.5513, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.4172, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.6459, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.6286646
0%| | 54/50000 [00:01<28:29, 29.22it/s]
MAE = tensor(0.0274, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0012, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0348, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03723942
0%| | 106/50000 [00:03<29:12, 28.48it/s]
MAE = tensor(0.0222, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0312, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.033968315
0%| | 156/50000 [00:05<30:24, 27.32it/s]
MAE = tensor(0.0206, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0304, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03331362
0%| | 205/50000 [00:07<30:23, 27.31it/s]
MAE = tensor(0.0198, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0302, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.033075716
1%| | 253/50000 [00:08<31:38, 26.20it/s]
MAE = tensor(0.0193, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0302, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03294569
1%| | 307/50000 [00:10<28:06, 29.46it/s]
MAE = tensor(0.0189, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0300, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03286848
1%| | 355/50000 [00:12<28:54, 28.62it/s]
MAE = tensor(0.0186, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0300, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03283855
1%| | 405/50000 [00:14<28:50, 28.67it/s]
MAE = tensor(0.0184, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0299, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032820173
1%| | 456/50000 [00:16<29:02, 28.43it/s]
MAE = tensor(0.0183, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0299, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032793105
1%| | 504/50000 [00:17<30:29, 27.05it/s]
MAE = tensor(0.0182, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0300, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03278664
1%| | 554/50000 [00:19<28:31, 28.89it/s]
MAE = tensor(0.0180, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0299, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032757252
1%| | 604/50000 [00:21<28:51, 28.53it/s]
MAE = tensor(0.0179, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0299, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032741934
1%|▏ | 655/50000 [00:22<29:42, 27.68it/s]
MAE = tensor(0.0178, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0298, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032745555
1%|▏ | 705/50000 [00:24<28:16, 29.06it/s]
MAE = tensor(0.0178, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0298, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032727756
2%|▏ | 755/50000 [00:26<28:16, 29.02it/s]
MAE = tensor(0.0177, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0298, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032722812
2%|▏ | 805/50000 [00:28<28:11, 29.08it/s]
MAE = tensor(0.0177, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0298, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032715403
2%|▏ | 856/50000 [00:29<28:10, 29.07it/s]
MAE = tensor(0.0176, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0298, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03271365
2%|▏ | 905/50000 [00:31<28:52, 28.34it/s]
MAE = tensor(0.0176, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0298, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032711506
2%|▏ | 954/50000 [00:33<28:11, 28.99it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0298, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03271061
2%|▏ | 1004/50000 [00:35<27:46, 29.39it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0298, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032706123
2%|▏ | 1057/50000 [00:37<28:57, 28.17it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0298, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032691285
2%|▏ | 1104/50000 [00:38<29:53, 27.26it/s]
MAE = tensor(0.0173, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03225855
2%|▏ | 1155/50000 [00:40<28:39, 28.41it/s]
MAE = tensor(0.0172, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032255854
2%|▏ | 1205/50000 [00:42<29:32, 27.53it/s]
MAE = tensor(0.0172, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032254238
3%|▎ | 1254/50000 [00:44<29:44, 27.31it/s]
MAE = tensor(0.0172, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032252725
3%|▎ | 1306/50000 [00:45<27:48, 29.18it/s]
MAE = tensor(0.0172, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032251894
3%|▎ | 1355/50000 [00:47<27:44, 29.23it/s]
MAE = tensor(0.0172, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032246973
3%|▎ | 1407/50000 [00:49<27:11, 29.78it/s]
MAE = tensor(0.0172, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032246232
3%|▎ | 1455/50000 [00:50<29:14, 27.67it/s]
MAE = tensor(0.0172, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032244343
3%|▎ | 1507/50000 [00:52<28:31, 28.34it/s]
MAE = tensor(0.0172, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032243885
3%|▎ | 1554/50000 [00:54<29:03, 27.79it/s]
MAE = tensor(0.0172, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03224293
3%|▎ | 1603/50000 [00:56<27:52, 28.94it/s]
MAE = tensor(0.0172, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032242775
3%|▎ | 1655/50000 [00:57<27:24, 29.41it/s]
MAE = tensor(0.0171, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03224223
3%|▎ | 1704/50000 [00:59<29:26, 27.34it/s]
MAE = tensor(0.0171, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032242108
4%|▎ | 1755/50000 [01:01<28:27, 28.25it/s]
MAE = tensor(0.0171, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03224184
4%|▎ | 1803/50000 [01:03<27:55, 28.77it/s]
MAE = tensor(0.0171, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03224177
4%|▎ | 1856/50000 [01:05<28:42, 27.95it/s]
MAE = tensor(0.0171, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032241616
4%|▍ | 1904/50000 [01:06<29:04, 27.56it/s]
MAE = tensor(0.0171, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032241583
4%|▍ | 1954/50000 [01:08<28:03, 28.53it/s]
MAE = tensor(0.0171, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.0322415
4%|▍ | 2004/50000 [01:10<27:31, 29.06it/s]
MAE = tensor(0.0171, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03224148
4%|▍ | 2056/50000 [01:12<28:37, 27.92it/s]
MAE = tensor(0.0171, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032241438
4%|▍ | 2104/50000 [01:13<28:04, 28.43it/s]
MAE = tensor(0.0171, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032241423
4%|▍ | 2155/50000 [01:15<26:46, 29.77it/s]
MAE = tensor(0.0171, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.0322414
4%|▍ | 2204/50000 [01:17<26:42, 29.83it/s]
MAE = tensor(0.0171, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032241393
5%|▍ | 2257/50000 [01:19<27:29, 28.94it/s]
MAE = tensor(0.0171, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03224138
5%|▍ | 2305/50000 [01:20<29:00, 27.40it/s]
MAE = tensor(0.0171, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032241378
5%|▍ | 2356/50000 [01:22<27:29, 28.89it/s]
MAE = tensor(0.0171, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032241367
5%|▍ | 2404/50000 [01:24<28:15, 28.07it/s]
MAE = tensor(0.0171, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032241367
5%|▍ | 2456/50000 [01:26<28:01, 28.27it/s]
MAE = tensor(0.0171, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032241367
5%|▌ | 2503/50000 [01:28<29:26, 26.88it/s]
MAE = tensor(0.0171, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.032241363
5%|▌ | 2544/50000 [01:29<27:54, 28.34it/s]
Minimum learning rate reached, stopping the optimization
2544
2544 tensor(0.0171, device='cuda:0', grad_fn=<MeanBackward0>) tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) tensor(0.0295, device='cuda:0', grad_fn=<SqrtBackward0>) 0.032241363
89.7808678150177
📊 Visualize Training Loss and CNN-Predicted Parameter Maps
In this final section, we evaluate the performance of the trained PeakFitCNN model by visualizing both the training history and the reconstructed peak parameter maps.
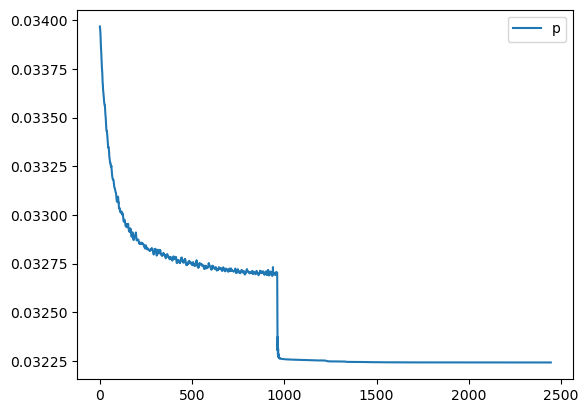
📉 Loss Curve
We first plot the logged RMSE loss (logloss) across training epochs (starting from epoch 100 for clarity). This helps verify whether the model has converged and how stable the optimization process was.
🗺️ Extract Predicted Parameters from CNN
After training, we extract the output from the model:
The raw predicted maps are optionally smoothed using a
3×3average filter.Each parameter map (area, position, FWHM, slope, intercept) is denormalized to recover physical units.
The output maps are spatially cropped to remove padding (based on the difference in shape between predicted and ground truth volumes).
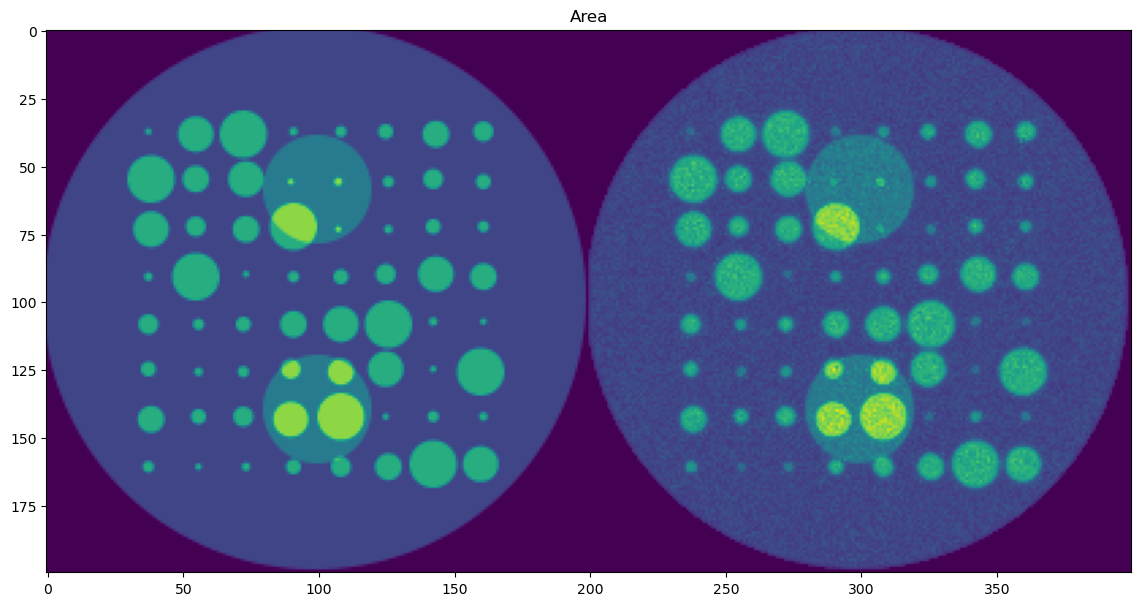
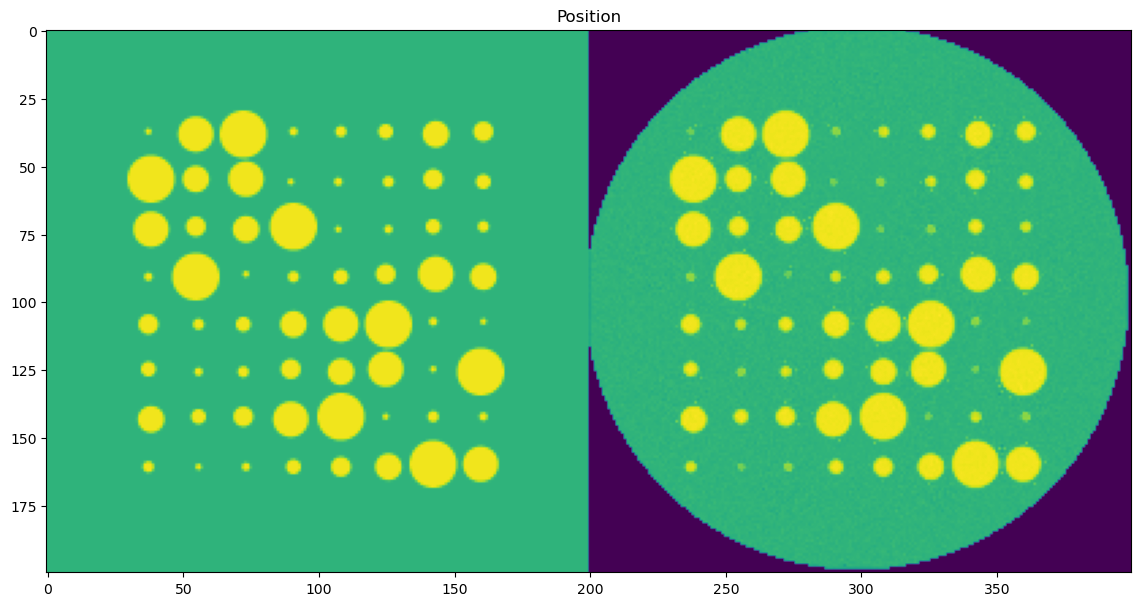
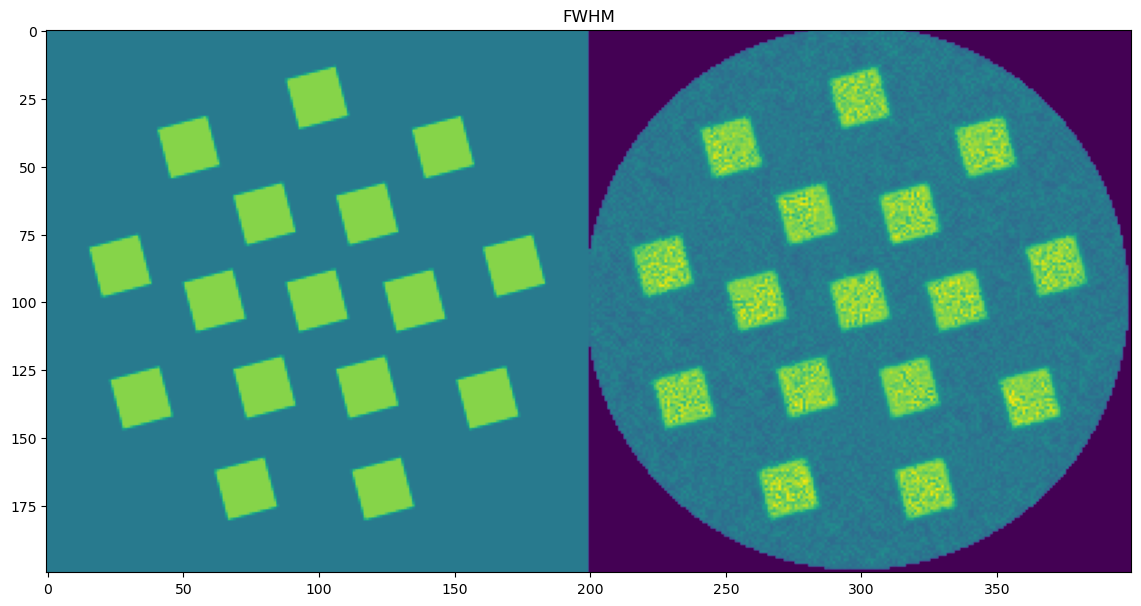
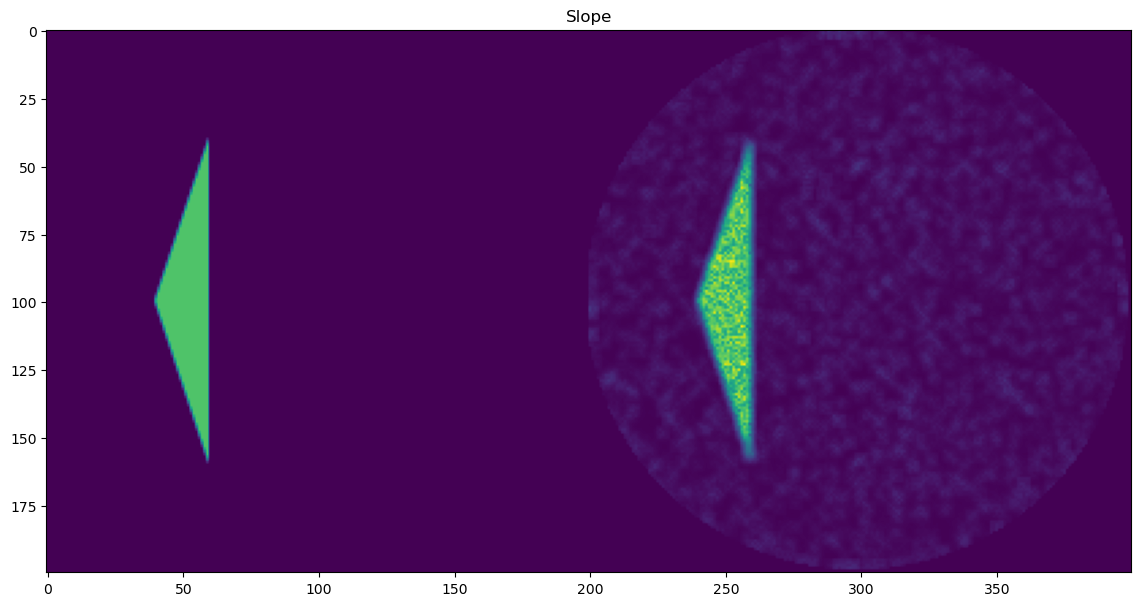
🎯 Masked Comparison and Visual Output
To compare the CNN results with the ground truth:
A mask is applied to focus only on the regions where meaningful signal exists (i.e., where
peak_area > 0.1).The CNN-predicted maps are concatenated side-by-side with the corresponding ground truth maps for visual inspection.
This comparison is done for all five parameters:
Peak Area
Peak Position
Peak FWHM
Background Slope
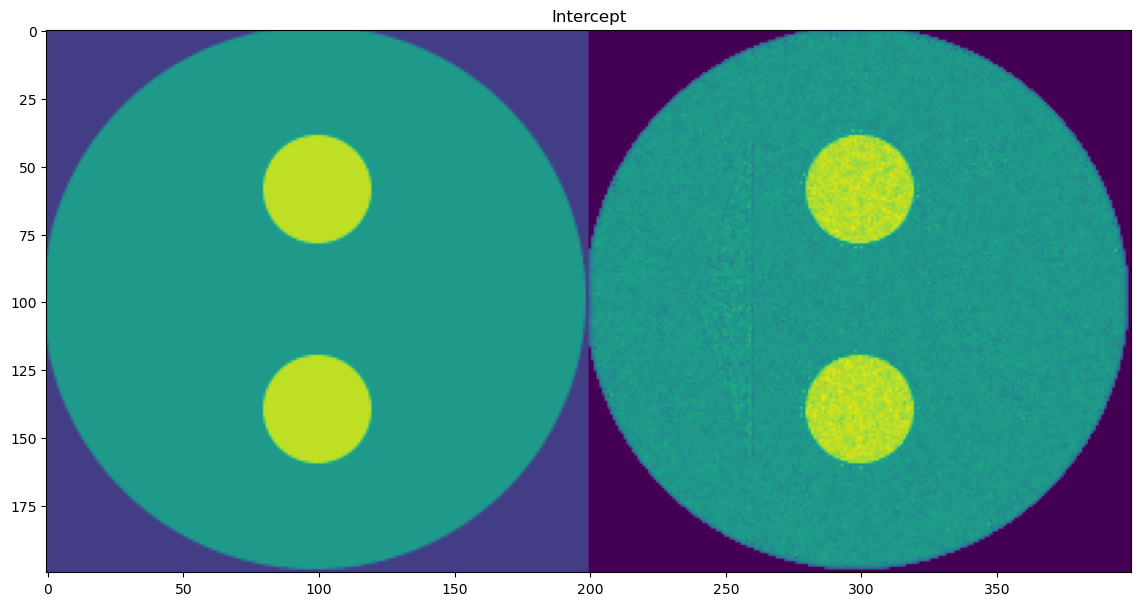
Background Intercept
Each parameter is shown as a 2D image, where the left half corresponds to the ground truth and the right half shows the PeakFitCNN prediction (masked to remove background).
These visualizations help assess both spatial fidelity and denoising performance of the CNN-based peak fitting approach.
[ ]:
%matplotlib inline
plt.figure(1);plt.clf()
plt.plot(logloss[100:])
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.show()
ims = model(im_static)
filtered = nn.AvgPool2d(kernel_size=5, stride=1, padding=2)(ims)
lower_bound = filtered * (1 - prf)
upper_bound = filtered * (1 + prf)
ims = torch.clamp(ims, min=lower_bound, max=upper_bound)
i = 0
prms_peak1_area = denormalize(ims[:, i * 3, :, :], 'Area', param_min, param_max, i)[0,:,:].cpu().detach().numpy()
prms_peak1_pos = denormalize(ims[:, i * 3 + 1, :, :], 'Position', param_min, param_max, i)[0,:,:].cpu().detach().numpy()
prms_peak1_fwhm = denormalize(ims[:, i * 3 + 2, :, :], 'FWHM', param_min, param_max, i)[0,:,:].cpu().detach().numpy()
prms_slope = denormalize(ims[:, -2, :, :], 'Slope', param_min, param_max, )[0,:,:].cpu().detach().numpy()
prms_intercept = denormalize(ims[:, -1, :, :], 'Intercept', param_min, param_max, )[0,:,:].cpu().detach().numpy()
ofs = int((prms_peak1_area.shape[0] - peak_area.shape[0])/2)
prms_peak1_area = prms_peak1_area[ofs:prms_peak1_area.shape[0]-ofs, ofs:prms_peak1_area.shape[1]-ofs]
prms_peak1_pos = prms_peak1_pos[ofs:prms_peak1_pos.shape[0]-ofs, ofs:prms_peak1_pos.shape[1]-ofs]
prms_peak1_fwhm = prms_peak1_fwhm[ofs:prms_peak1_fwhm.shape[0]-ofs, ofs:prms_peak1_fwhm.shape[1]-ofs]
prms_slope = prms_slope[ofs:prms_slope.shape[0]-ofs, ofs:prms_slope.shape[1]-ofs]
prms_intercept = prms_intercept[ofs:prms_intercept.shape[0]-ofs, ofs:prms_intercept.shape[1]-ofs]
print(prms_peak1_area.shape, prms_peak1_pos.shape, prms_peak1_fwhm.shape, prms_slope.shape, prms_intercept.shape)
msk = np.copy(peak_area)
msk[msk<0.1] = 0
msk[msk>0] = 1
areac = np.concatenate((peak_area, prms_peak1_area*msk), axis = 1)
posc = np.concatenate((peak_position, prms_peak1_pos*msk), axis = 1)
fwhmc = np.concatenate((peak_fwhm, prms_peak1_fwhm*msk), axis = 1)
slopec = np.concatenate((peak_slope, prms_slope*msk), axis = 1)
interceptc = np.concatenate((peak_intercept, prms_intercept*msk), axis = 1)
plt.figure(1, figsize=(14,14));plt.clf()
plt.imshow(areac)
# plt.colorbar()
plt.title('Area')
plt.show()
plt.figure(2, figsize=(14,14));plt.clf()
plt.imshow(posc)
# plt.colorbar()
plt.title('Position')
plt.show()
plt.figure(3, figsize=(14,14));plt.clf()
plt.imshow(fwhmc)
# plt.colorbar()
plt.title('FWHM')
plt.show()
plt.figure(4, figsize=(14,14));plt.clf()
plt.imshow(slopec)
# plt.colorbar()
plt.title('Slope')
plt.show()
plt.figure(5, figsize=(14,14));plt.clf()
plt.imshow(interceptc)
# plt.colorbar()
plt.title('Intercept')
plt.show()
(304, 304) (304, 304) (304, 304) (304, 304) (304, 304)
(200, 200) (200, 200) (200, 200) (200, 200) (200, 200)
52
(200, 200) (200, 200) (200, 200) (200, 200) (200, 200)
🧠 Define and Prepare PeakFitCNN for Self-Supervised Training from Downsampled Input
We now instantiate the PeakFitCNN model that performs self-supervised peak fitting directly from 4× downsampled hyperspectral data. This model is designed to replace the parameter map initialization used earlier with a CNN that learns the full-resolution parameter maps from a coarse input.
🏗️ Model Configuration
nch_in: Number of input spectral channels (i.e., length of diffraction axis)nch_out: Number of predicted parameter maps (total of 5)nfilts: Number of filters in each layer; here set to match the number of input channelsupscale_factor: 4× spatial upsampling to recover full-resolution outputnorm_type: Instance normalization for stabilityactivation: Sigmoid activation ensures output values are bounded in [0, 1]
The total number of trainable parameters in the CNN is printed and compared against the number of parameters used in the conventional approach, which stores a separate value per parameter per voxel.
🔄 Prepare Inputs for CNN
We convert the original noisy 3D hyperspectral volume (volp) into a 4D tensor and spatially downsample it by a factor of 4 using bilinear interpolation. This downsampled input will be fed to the CNN to predict the full-resolution parameter maps.
This approach allows the model to:
Exploit spatial context via convolution
Combine denoising, peak fitting, and resolution enhancement in a single learned model
The shapes of both full-resolution and downsampled tensors are printed for verification.
[8]:
model_cnn = PeakFitCNN(nch_in=volp.shape[2], nch_out=nch_out, nfilts=64, upscale_factor = 4, norm_type='instance',
activation='Sigmoid', padding='same').to(device)
nch_in = volp.shape[2]
nfilts = volp.shape[2] # 2*total_params
# Calculate the total number of parameters
model_prms = sum(p.numel() for p in model_cnn.parameters() if p.requires_grad)
print(f"Total number of parameters: {model_prms}")
print('Number of filters:', nfilts)
print(nch_out, npix)
print("Conventional number of parameters:", npix*npix*total_params)
yobs = np.transpose(volp, (2,1,0))
yobs = torch.tensor(yobs, dtype=torch.float32, device=device)
yobs = torch.reshape(yobs, (1, yobs.shape[0], yobs.shape[1], yobs.shape[2]))
yobs = torch.transpose(yobs, 3, 2)
downsampled = F.interpolate(yobs, scale_factor=1/4, mode='bilinear', align_corners=False)
print(downsampled.shape, yobs.shape, yobs.shape[2]/4)
Total number of parameters: 105861
Number of filters: 50
5 304
Conventional number of parameters: 462080
torch.Size([1, 50, 76, 76]) torch.Size([1, 50, 304, 304]) 76.0
🔁 Train PeakFitCNN from Downsampled Hyperspectral Input
We now train the PeakFitCNN model using the 4× downsampled hyperspectral input volume. This deep-learning approach replaces explicit parameter map initialization with a CNN trained end-to-end to predict all peak parameters.
The training follows the same self-supervised spectral reconstruction strategy as before, but now the input is downsampled data and the model itself performs both super-resolution and peak fitting.
⚙️ Training Configuration
epochs = 50000: maximum number of training epochsprf = 0.2: ±20% soft constraint around local average predictions to stabilize trainingpatience = 200: used by the learning rate scheduler to detect plateausoptimizer: Adam with an initial learning rate of0.001scheduler: learning rate is halved on plateaus, down to a minimum of1e-5num_patches: number of spatial patches processed per batch
🧠 Training Loop
For each epoch:
A forward pass is performed using the downsampled hyperspectral data as input.
The CNN predicts full-resolution normalized parameter maps (
yc).A local average filter is applied, and values are clamped within ±20% of the smoothed estimates.
Spectral reconstruction is done using the same Gaussian + linear background model.
Random patches of the predicted and ground truth spectra are extracted.
The RMSE loss is computed between predicted and true spectra, and used for backpropagation.
The loop continues until convergence or the minimum learning rate is reached.
📈 Output
At the end of training, the code logs:
Final epoch count
Final MAE, MSE, RMSE
Total training time in seconds
A full log of the RMSE loss at each epoch (
logloss), which can later be plotted to assess convergence
This completes the training of the second fitting approach, where PeakFitCNN directly learns to denoise and fit peak parameters from low-resolution hyperspectral input.
[9]:
nch = volp.shape[2]
learning_rate = 0.001
epochs = 10000
min_lr = 1E-5
yobs = np.transpose(volp, (2,1,0))
yobs = torch.tensor(yobs, dtype=torch.float32, device=device)
yobs = torch.reshape(yobs, (1, yobs.shape[0], yobs.shape[1], yobs.shape[2]))
yobs = torch.transpose(yobs, 3, 2)
prf = 0.2
epochs = 50000
patience = 200
learning_rate = 0.001
min_lr = 1E-5
optimizer = torch.optim.Adam(model_cnn.parameters(), lr=learning_rate)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, patience=patience, factor=0.5, min_lr=min_lr)
num_patches = 16
new_indices = np.array(indices)
total_indices = len(indices)
num_batches = (total_indices + num_patches - 1) // num_patches
print(num_batches)
start = time.time()
logloss = []
for epoch in tqdm(range(epochs)):
loss_acc = 0
for batch_index in range(num_batches):
start_index = batch_index * num_patches
end_index = min(start_index + num_patches, total_indices)
batch_indices = new_indices[start_index:end_index]
yc = model_cnn(downsampled)
filtered = nn.AvgPool2d(kernel_size=3, stride=1, padding=1)(yc)
lower_bound = filtered * (1.0 - prf)
upper_bound = filtered * (1.0 + prf)
yc = torch.clamp(yc, min=lower_bound, max=upper_bound)
yc = calc_patches_indices(batch_indices, yc, patch_size, use_middle=False)
y = torch.zeros((patch_size*patch_size*len(batch_indices), len(xv)), dtype=torch.float32).to(device)
for i in range(num_peaks):
area = denormalize(yc[:, i * 3, :, :], 'Area', param_min, param_max, i)
position = denormalize(yc[:, i * 3 + 1, :, :], 'Position', param_min, param_max, i)
fwhm = denormalize(yc[:, i * 3 + 2, :, :], 'FWHM', param_min, param_max, i)
area = torch.transpose(torch.reshape(area, (area.shape[0], area.shape[1]*area.shape[2])), 1, 0)
position = torch.transpose(torch.reshape(position, (position.shape[0], position.shape[1]*position.shape[2])), 1, 0)
fwhm = torch.transpose(torch.reshape(fwhm, (fwhm.shape[0], fwhm.shape[1]*fwhm.shape[2])), 1, 0)
area = torch.reshape(area, (area.shape[0]*area.shape[1], 1))
position = torch.reshape(position, (area.shape[0]*area.shape[1], 1))
fwhm = torch.reshape(fwhm, (area.shape[0]*area.shape[1], 1))
y += gaussian(xv.unsqueeze(0), area, position, fwhm)
slope = denormalize(yc[:, -2, :, :], 'Slope', param_min, param_max, )
intercept = denormalize(yc[:, -1, :, :], 'Intercept', param_min, param_max, )
slope = torch.transpose(torch.reshape(slope, (slope.shape[0], slope.shape[1]*slope.shape[2])), 1, 0)
intercept = torch.transpose(torch.reshape(intercept, (intercept.shape[0], intercept.shape[1]*intercept.shape[2])), 1, 0)
slope = torch.reshape(slope, (slope.shape[0]*slope.shape[1], 1))
intercept = torch.reshape(intercept, (intercept.shape[0]*intercept.shape[1], 1))
y += slope * xv + intercept
patches = calc_patches_indices(batch_indices, yobs, patch_size, use_middle=False)
patches = torch.reshape(patches, (patches.shape[0],patches.shape[1],patches.shape[2]*patches.shape[3]))
patches = torch.transpose(patches, 1, 2)
patches = torch.transpose(patches, 1, 0)
y = torch.reshape(y, (patches.shape[0], patches.shape[1], nch))
loss_mae = MAE(patches, y)
loss_mse = torch.mean((patches - y) ** 2)
loss_rmse = torch.sqrt(torch.mean((patches - y) ** 2))
loss_acc = loss_acc + loss_rmse
loss = loss_rmse
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_acc = loss_acc/num_batches
logloss.append(loss_acc.cpu().detach().numpy())
scheduler.step(logloss[-1])
if epoch % (int(patience/2)) == 0:
print('MAE = ', loss_mae, 'MSE = ', loss_mse,'RMSE = ', loss_rmse)
print('Accumulated Loss = ', logloss[-1])
if optimizer.param_groups[0]['lr'] == scheduler.min_lrs[0]:
print("Minimum learning rate reached, stopping the optimization")
print(epoch)
break
total_time = time.time() - start
print(epoch, loss_mae, loss_mse, loss_rmse, logloss[-1])
print(total_time)
4
0%| | 3/50000 [00:01<6:56:50, 2.00it/s]
MAE = tensor(0.3333, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.2001, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.4473, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.5270382
0%| | 103/50000 [00:08<50:36, 16.43it/s]
MAE = tensor(0.0212, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0017, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0412, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.050710965
0%| | 203/50000 [00:14<50:40, 16.38it/s]
MAE = tensor(0.0196, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0013, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0359, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.045893442
1%| | 303/50000 [00:20<50:11, 16.50it/s]
MAE = tensor(0.0190, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0012, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0346, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.045011953
1%| | 403/50000 [00:26<53:52, 15.34it/s]
MAE = tensor(0.0191, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0012, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0345, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.04258658
1%| | 503/50000 [00:33<52:24, 15.74it/s]
MAE = tensor(0.0185, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0011, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0333, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.040656906
1%| | 603/50000 [00:39<52:44, 15.61it/s]
MAE = tensor(0.0193, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0013, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0366, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.041201398
1%|▏ | 703/50000 [00:45<51:37, 15.92it/s]
MAE = tensor(0.0182, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0011, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0325, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03891048
2%|▏ | 803/50000 [00:52<51:46, 15.84it/s]
MAE = tensor(0.0184, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0011, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0327, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.038208865
2%|▏ | 903/50000 [00:58<50:36, 16.17it/s]
MAE = tensor(0.0181, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0323, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.037678964
2%|▏ | 1003/50000 [01:04<51:05, 15.98it/s]
MAE = tensor(0.0183, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0011, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0331, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.0373457
2%|▏ | 1103/50000 [01:10<50:30, 16.14it/s]
MAE = tensor(0.0180, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0323, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.036977306
2%|▏ | 1203/50000 [01:17<50:05, 16.24it/s]
MAE = tensor(0.0183, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0011, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0328, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03719177
3%|▎ | 1303/50000 [01:23<50:59, 15.92it/s]
MAE = tensor(0.0180, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0321, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.036611665
3%|▎ | 1403/50000 [01:29<51:34, 15.70it/s]
MAE = tensor(0.0180, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0011, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0324, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.036600217
3%|▎ | 1503/50000 [01:36<51:10, 15.79it/s]
MAE = tensor(0.0179, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0318, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03629551
3%|▎ | 1603/50000 [01:42<51:28, 15.67it/s]
MAE = tensor(0.0180, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0321, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03647107
3%|▎ | 1703/50000 [01:48<51:29, 15.63it/s]
MAE = tensor(0.0179, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0318, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.035863187
4%|▎ | 1803/50000 [01:54<48:44, 16.48it/s]
MAE = tensor(0.0178, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0317, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.035995953
4%|▍ | 1903/50000 [02:01<49:20, 16.25it/s]
MAE = tensor(0.0177, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0315, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03563793
4%|▍ | 2003/50000 [02:07<52:03, 15.37it/s]
MAE = tensor(0.0178, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0316, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.035724286
4%|▍ | 2103/50000 [02:13<44:50, 17.80it/s]
MAE = tensor(0.0177, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0315, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.035693996
4%|▍ | 2203/50000 [02:19<43:37, 18.26it/s]
MAE = tensor(0.0177, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0315, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.035871103
5%|▍ | 2303/50000 [02:25<49:36, 16.02it/s]
MAE = tensor(0.0176, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0313, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03509817
5%|▍ | 2403/50000 [02:31<48:11, 16.46it/s]
MAE = tensor(0.0176, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0313, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03498531
5%|▌ | 2503/50000 [02:37<50:24, 15.71it/s]
MAE = tensor(0.0177, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0314, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03500544
5%|▌ | 2603/50000 [02:43<51:37, 15.30it/s]
MAE = tensor(0.0177, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0313, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034952197
5%|▌ | 2703/50000 [02:49<48:19, 16.31it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0312, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034724616
6%|▌ | 2803/50000 [02:56<47:55, 16.41it/s]
MAE = tensor(0.0176, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0312, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034870118
6%|▌ | 2903/50000 [03:02<49:53, 15.73it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0312, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034674354
6%|▌ | 3003/50000 [03:08<47:49, 16.38it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0312, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03468612
6%|▌ | 3103/50000 [03:14<47:27, 16.47it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0312, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034651715
6%|▋ | 3203/50000 [03:20<47:25, 16.45it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0312, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034653593
7%|▋ | 3303/50000 [03:26<49:46, 15.63it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0312, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.0346579
7%|▋ | 3403/50000 [03:33<47:19, 16.41it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0311, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03460689
7%|▋ | 3503/50000 [03:39<48:45, 15.89it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0311, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03456475
7%|▋ | 3603/50000 [03:45<48:41, 15.88it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0311, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03459655
7%|▋ | 3703/50000 [03:51<47:58, 16.08it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0311, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034563337
8%|▊ | 3803/50000 [03:58<47:09, 16.33it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0311, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.0345636
8%|▊ | 3903/50000 [04:04<46:40, 16.46it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0312, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034614798
8%|▊ | 4003/50000 [04:10<46:33, 16.47it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0311, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034512524
8%|▊ | 4103/50000 [04:16<48:42, 15.70it/s]
MAE = tensor(0.0176, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0312, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034549214
8%|▊ | 4203/50000 [04:22<49:06, 15.54it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0310, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03445877
9%|▊ | 4303/50000 [04:28<45:52, 16.60it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0311, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034504306
9%|▉ | 4403/50000 [04:35<48:03, 15.82it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0311, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034519542
9%|▉ | 4503/50000 [04:41<48:29, 15.64it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0310, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034528535
9%|▉ | 4603/50000 [04:47<45:59, 16.45it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0310, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.0344528
9%|▉ | 4703/50000 [04:53<46:59, 16.07it/s]
MAE = tensor(0.0175, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0310, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034418907
10%|▉ | 4803/50000 [04:59<47:24, 15.89it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0310, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034326527
10%|▉ | 4903/50000 [05:05<46:04, 16.31it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0310, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03433165
10%|█ | 5003/50000 [05:11<45:32, 16.47it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034307346
10%|█ | 5103/50000 [05:18<47:40, 15.70it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034301657
10%|█ | 5203/50000 [05:24<45:33, 16.39it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034297302
11%|█ | 5303/50000 [05:30<48:01, 15.51it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03429296
11%|█ | 5403/50000 [05:36<47:16, 15.72it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034296636
11%|█ | 5503/50000 [05:42<45:31, 16.29it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03429406
11%|█ | 5603/50000 [05:48<45:33, 16.24it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03427482
11%|█▏ | 5703/50000 [05:55<47:09, 15.66it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034265134
12%|█▏ | 5803/50000 [06:01<45:26, 16.21it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03427026
12%|█▏ | 5903/50000 [06:07<46:01, 15.97it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034256443
12%|█▏ | 6003/50000 [06:13<49:04, 14.94it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034247976
12%|█▏ | 6103/50000 [06:19<43:53, 16.67it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03425298
12%|█▏ | 6203/50000 [06:26<46:17, 15.77it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034239013
13%|█▎ | 6303/50000 [06:32<42:41, 17.06it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034230035
13%|█▎ | 6403/50000 [06:37<43:04, 16.87it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034233563
13%|█▎ | 6504/50000 [06:43<42:40, 16.99it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03423074
13%|█▎ | 6603/50000 [06:49<40:57, 17.66it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034222208
13%|█▎ | 6704/50000 [06:55<38:30, 18.74it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034213934
14%|█▎ | 6803/50000 [07:00<41:00, 17.56it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03420766
14%|█▍ | 6903/50000 [07:05<41:24, 17.35it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034205664
14%|█▍ | 7004/50000 [07:11<38:17, 18.71it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034200996
14%|█▍ | 7104/50000 [07:17<43:26, 16.46it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034197316
14%|█▍ | 7204/50000 [07:22<39:30, 18.05it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03419074
15%|█▍ | 7303/50000 [07:28<39:15, 18.12it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034189977
15%|█▍ | 7403/50000 [07:33<40:20, 17.60it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03418314
15%|█▌ | 7504/50000 [07:39<42:18, 16.74it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034182277
15%|█▌ | 7603/50000 [07:45<44:34, 15.85it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03417656
15%|█▌ | 7703/50000 [07:51<43:24, 16.24it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0309, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034172576
16%|█▌ | 7803/50000 [07:57<40:09, 17.51it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034168303
16%|█▌ | 7904/50000 [08:03<42:30, 16.51it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034163553
16%|█▌ | 8004/50000 [08:09<39:58, 17.51it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034164675
16%|█▌ | 8103/50000 [08:14<38:33, 18.11it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03416014
16%|█▋ | 8203/50000 [08:20<41:34, 16.76it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03416242
17%|█▋ | 8303/50000 [08:26<40:51, 17.01it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034155678
17%|█▋ | 8404/50000 [08:32<40:36, 17.07it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034150798
17%|█▋ | 8504/50000 [08:37<40:43, 16.98it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034144267
17%|█▋ | 8604/50000 [08:43<37:33, 18.37it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03414733
17%|█▋ | 8704/50000 [08:48<39:14, 17.54it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034143243
18%|█▊ | 8803/50000 [08:54<38:54, 17.65it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034140583
18%|█▊ | 8903/50000 [09:00<39:26, 17.37it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034139127
18%|█▊ | 9003/50000 [09:06<40:28, 16.88it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03413096
18%|█▊ | 9104/50000 [09:11<38:35, 17.66it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0010, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03413461
18%|█▊ | 9204/50000 [09:17<38:12, 17.79it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034122884
19%|█▊ | 9303/50000 [09:23<40:28, 16.76it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034123167
19%|█▉ | 9404/50000 [09:29<38:52, 17.40it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034123003
19%|█▉ | 9503/50000 [09:34<37:26, 18.03it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03410688
19%|█▉ | 9603/50000 [09:40<38:37, 17.43it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03410682
19%|█▉ | 9703/50000 [09:46<38:29, 17.45it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034103237
20%|█▉ | 9803/50000 [09:52<38:05, 17.59it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.03410216
20%|█▉ | 9904/50000 [09:57<37:46, 17.69it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034100927
20%|██ | 10004/50000 [10:03<39:02, 17.08it/s]
MAE = tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) MSE = tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) RMSE = tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>)
Accumulated Loss = 0.034099713
20%|██ | 10024/50000 [10:04<40:12, 16.57it/s]
Minimum learning rate reached, stopping the optimization
10024
10024 tensor(0.0174, device='cuda:0', grad_fn=<MeanBackward0>) tensor(0.0009, device='cuda:0', grad_fn=<MeanBackward0>) tensor(0.0308, device='cuda:0', grad_fn=<SqrtBackward0>) 0.03409917
604.8720400333405
🧪 Compare Parameter Maps from PeakFitCNN and Conventional Approach
After training the PeakFitCNN model on downsampled input, we now extract and visualize the predicted parameter maps. This section mirrors the post-processing used earlier for the conventional parameter maps, allowing for direct visual comparison.
📉 Loss Curve
We first plot the RMSE loss curve from the PeakFitCNN training (logloss), starting from epoch 100. This helps assess whether the model has converged and how its behavior compares to the conventional approach.
🗺️ Extract CNN-Predicted Parameters
We:
Perform a forward pass through the trained PeakFitCNN using the downsampled input
Apply local smoothing (
3×3average pooling)Clamp predictions within ±20% of the smoothed values
Denormalize all five parameter maps: area, position, FWHM, slope, and intercept
As before, we crop the output to remove padding (ofs) and apply a binary mask (msk) to focus only on relevant signal regions.
🔍 Side-by-Side Comparison
For each parameter, we concatenate the following maps side-by-side:
Ground truth from the simulation
Conventional parameter map (fit via
PrmCNN2D)CNN prediction (from PeakFitCNN)
These are visualized with imshow() using the 'jet' colormap to highlight spatial gradients.
This comparison allows us to qualitatively assess:
Fidelity to the true parameter maps
Degree of denoising
Spatial continuity and sharpness
[10]:
%matplotlib inline
plt.figure(1);plt.clf()
plt.plot(logloss[100:])
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.show()
ims = model_cnn(downsampled)
filtered = nn.AvgPool2d(kernel_size=3, stride=1, padding=1)(ims)
lower_bound = filtered * (1 - prf)
upper_bound = filtered * (1 + prf)
ims = torch.clamp(ims, min=lower_bound, max=upper_bound)
i = 0
cnn_peak1_area = denormalize(ims[:, i * 3, :, :], 'Area', param_min, param_max, i)[0,:,:].cpu().detach().numpy()
cnn_peak1_pos = denormalize(ims[:, i * 3 + 1, :, :], 'Position', param_min, param_max, i)[0,:,:].cpu().detach().numpy()
cnn_peak1_fwhm = denormalize(ims[:, i * 3 + 2, :, :], 'FWHM', param_min, param_max, i)[0,:,:].cpu().detach().numpy()
cnn_slope = denormalize(ims[:, -2, :, :], 'Slope', param_min, param_max, )[0,:,:].cpu().detach().numpy()
cnn_intercept = denormalize(ims[:, -1, :, :], 'Intercept', param_min, param_max, )[0,:,:].cpu().detach().numpy()
ofs = int((cnn_peak1_area.shape[0] - peak_area.shape[0])/2)
print(ofs)
cnn_peak1_area = cnn_peak1_area[ofs:cnn_peak1_area.shape[0]-ofs, ofs:cnn_peak1_area.shape[1]-ofs]
cnn_peak1_pos = cnn_peak1_pos[ofs:cnn_peak1_pos.shape[0]-ofs, ofs:cnn_peak1_pos.shape[1]-ofs]
cnn_peak1_fwhm = cnn_peak1_fwhm[ofs:cnn_peak1_fwhm.shape[0]-ofs, ofs:cnn_peak1_fwhm.shape[1]-ofs]
cnn_slope = cnn_slope[ofs:cnn_slope.shape[0]-ofs, ofs:cnn_slope.shape[1]-ofs]
cnn_intercept = cnn_intercept[ofs:cnn_intercept.shape[0]-ofs, ofs:cnn_intercept.shape[1]-ofs]
msk = np.copy(peak_area)
msk[msk<0.1] = 0
msk[msk>0] = 1
print(peak_area.shape, prms_peak1_area.shape, cnn_peak1_area.shape)
areac = np.concatenate((peak_area*msk, prms_peak1_area*msk, cnn_peak1_area*msk), axis = 1)
posc = np.concatenate((peak_position*msk, prms_peak1_pos*msk, cnn_peak1_pos*msk), axis = 1)
fwhmc = np.concatenate((peak_fwhm*msk, prms_peak1_fwhm*msk, cnn_peak1_fwhm*msk), axis = 1)
slopec = np.concatenate((peak_slope*msk, prms_slope*msk, cnn_slope*msk), axis = 1)
interceptc = np.concatenate((peak_intercept*msk, prms_intercept*msk, cnn_intercept*msk), axis = 1)
plt.figure(1, figsize=(14,14));plt.clf()
plt.imshow(areac, cmap = 'jet')
# plt.colorbar()
plt.title('Area')
plt.show()
plt.figure(2, figsize=(14,14));plt.clf()
plt.imshow(posc, cmap = 'jet')
# plt.colorbar()
plt.title('Position')
plt.show()
plt.figure(3, figsize=(14,14));plt.clf()
plt.imshow(fwhmc, cmap = 'jet')
# plt.colorbar()
plt.title('FWHM')
plt.show()
plt.figure(4, figsize=(14,14));plt.clf()
plt.imshow(slopec, cmap = 'jet')
# plt.colorbar()
plt.title('Slope')
plt.show()
plt.figure(5, figsize=(14,14));plt.clf()
plt.imshow(interceptc, cmap = 'jet')
# plt.colorbar()
plt.title('Intercept')
plt.show()
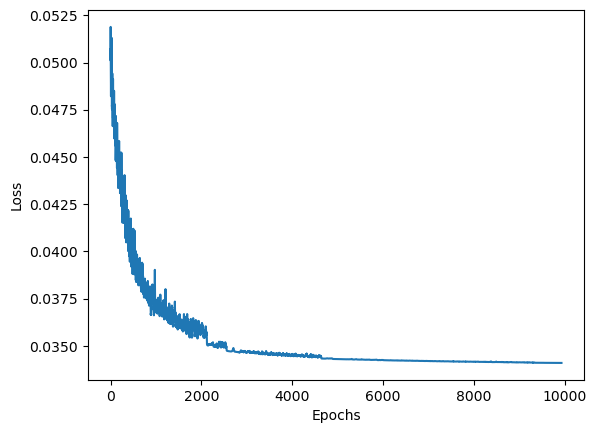
52
(200, 200) (200, 200) (200, 200)
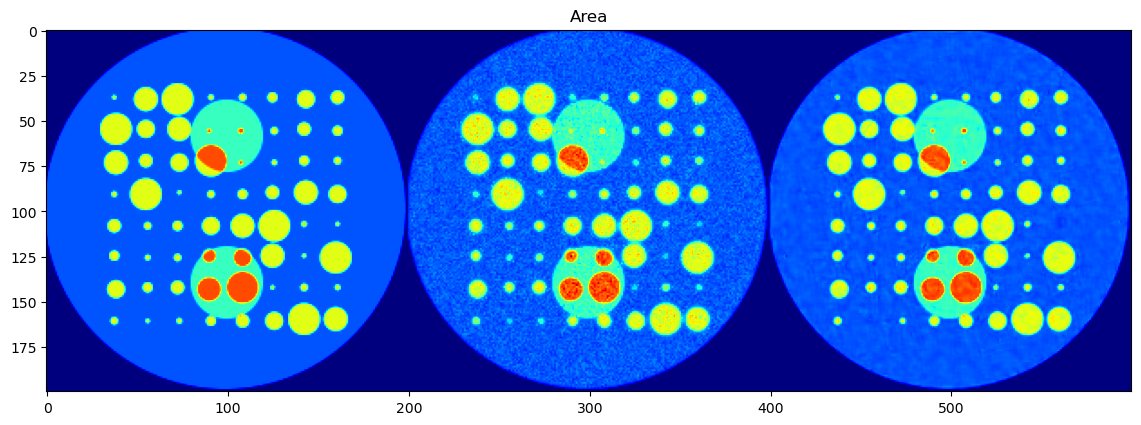
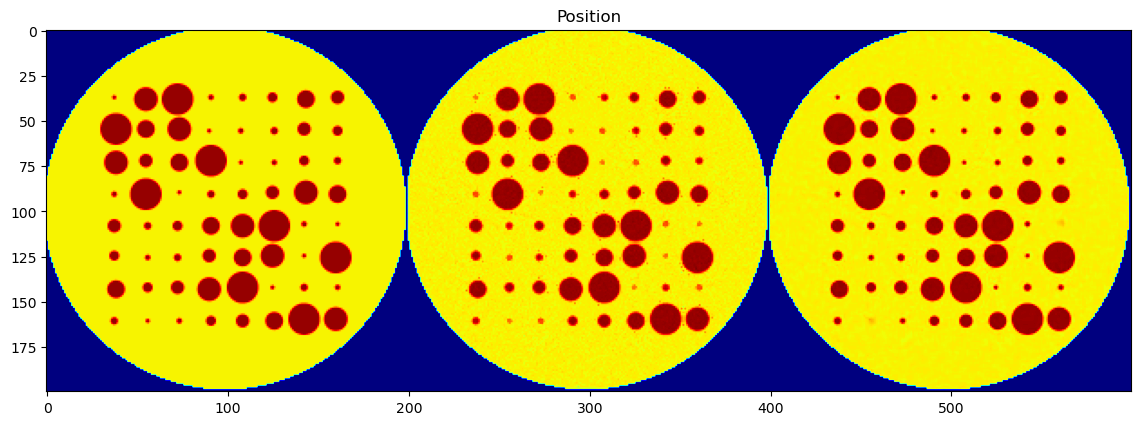
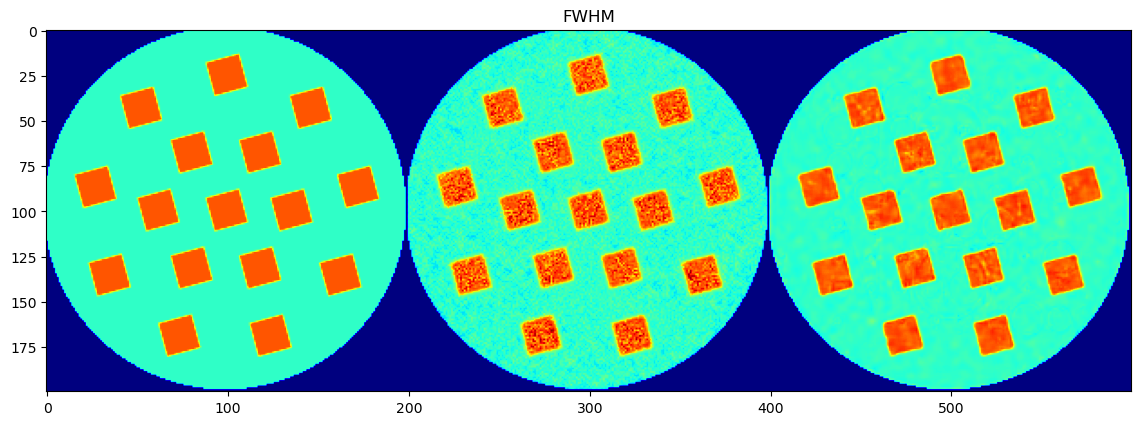
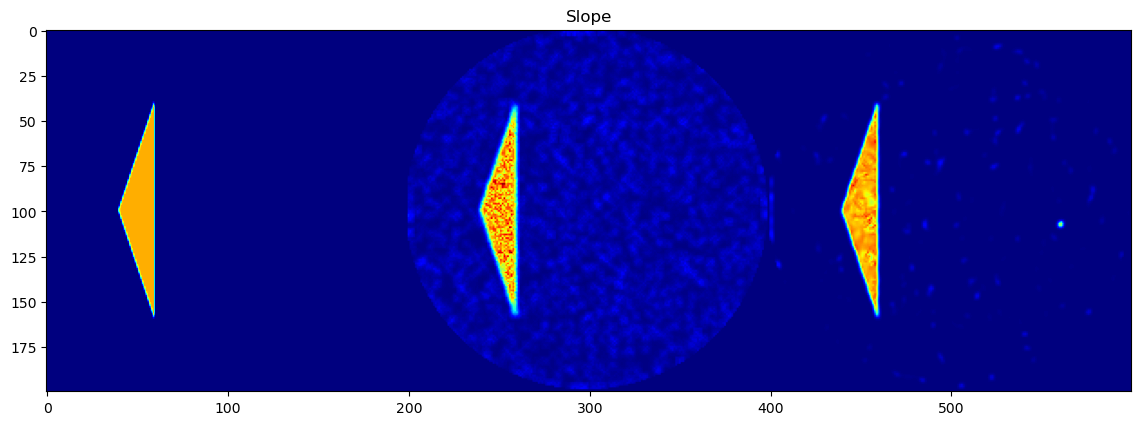
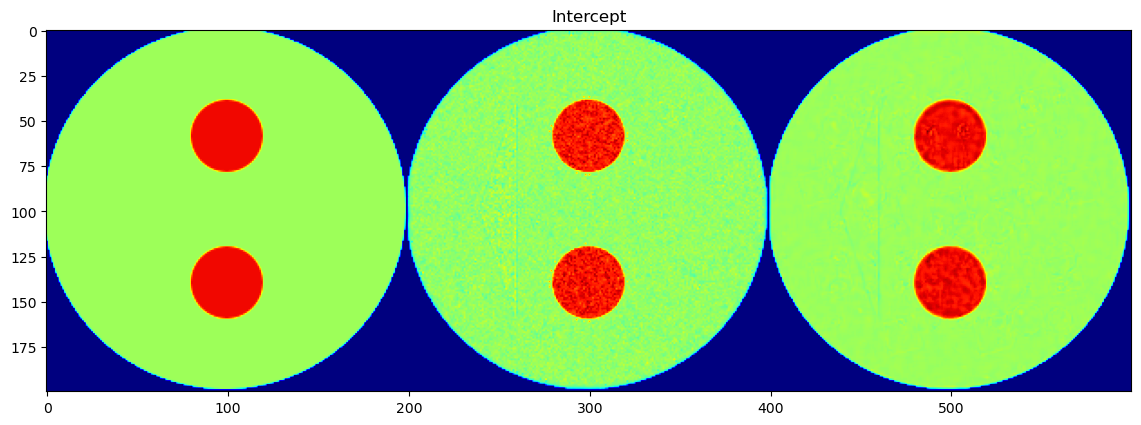
💾 Save Processed Parameter Maps to HDF5
To facilitate downstream analysis and reproducibility, we save all relevant parameter maps to an HDF5 file (peak_fit_cnn_results.h5). This includes:
Ground truth maps (
*_gt) from the synthetic simulationCNN predictions (
*_cnn) obtained from the trainedPeakFitCNNConventional estimates (
*_prms) fromPrmCNN2DSide-by-side concatenated maps (
*_concat) used for visualization
All maps are masked (msk) to include only signal-rich regions. The file is stored in the examples/results/ directory of the nDTomo package using a relative path resolved by ndtomopath().
This step ensures a compact, structured format for easy sharing, reproducibility, and integration with other analysis or visualization tools.
[11]:
import h5py, os
from nDTomo.methods.misc import ndtomopath
fn = os.path.join(ndtomopath(), 'examples', 'results', 'peak_fit_cnn_results.h5')
with h5py.File(fn, 'w') as f:
f.create_dataset('peak_area_gt', data=peak_area*msk)
f.create_dataset('peak_area_cnn', data=cnn_peak1_area*msk)
f.create_dataset('peak_area_prms', data=prms_peak1_area*msk)
f.create_dataset('peak_position_gt', data=peak_position*msk)
f.create_dataset('peak_position_cnn', data=cnn_peak1_pos*msk)
f.create_dataset('peak_position_prms', data=prms_peak1_pos*msk)
f.create_dataset('peak_fwhm_gt', data=peak_fwhm*msk)
f.create_dataset('peak_fwhm_cnn', data=cnn_peak1_fwhm*msk)
f.create_dataset('peak_fwhm_prms', data=prms_peak1_fwhm*msk)
f.create_dataset('peak_slope_gt', data=peak_slope*msk)
f.create_dataset('peak_slope_cnn', data=cnn_slope*msk)
f.create_dataset('peak_slope_prms', data=prms_slope*msk)
f.create_dataset('peak_intercept_gt', data=peak_intercept*msk)
f.create_dataset('peak_intercept_cnn', data=cnn_intercept*msk)
f.create_dataset('peak_intercept_prms', data=prms_intercept*msk)
f.create_dataset('peak_area_concat', data=areac)
f.create_dataset('peak_position_concat', data=posc)
f.create_dataset('peak_fwhm_concat', data=fwhmc)
f.create_dataset('peak_slope_concat', data=slopec)
f.create_dataset('peak_intercept_concat', data=interceptc)
📏 Define Evaluation Metrics
To quantitatively compare the CNN-predicted and conventionally fitted parameter maps against the ground truth, we implement the following standard image quality metrics using NumPy and scikit-image:
- MAE (Mean Absolute Error):Measures the average absolute difference between the predicted and ground truth values.
- MSE (Mean Squared Error):Measures the average of the squared differences, penalizing larger errors more heavily.
- RMSE (Root Mean Squared Error):The square root of MSE. While MSE penalizes larger errors more heavily due to squaring, RMSE transforms the result back to the original data scale, making it easier to interpret. It retains the sensitivity to large errors but is more directly comparable to the magnitude of the target values.
- PSNR (Peak Signal-to-Noise Ratio):Indicates the ratio between the maximum possible signal and the noise introduced by prediction errors. Higher values imply better fidelity.
SSIM (Structural Similarity Index): Evaluates perceived quality by comparing local patterns of pixel intensities. It accounts for luminance, contrast, and structural differences.
[19]:
import numpy as np
from skimage.metrics import structural_similarity as ssim_skimage
def mae(gt, pred):
return np.mean(np.abs(gt - pred))
def mse(gt, pred):
return np.mean((gt - pred)**2)
def rmse(gt, pred):
return np.sqrt(mse(gt, pred))
def psnr(gt, pred, data_range=None):
if data_range is None:
data_range = gt.max() - gt.min()
return 20 * np.log10(data_range) - 10 * np.log10(mse(gt, pred))
def ssim(gt, pred, data_range=None):
if data_range is None:
data_range = gt.max() - gt.min()
return ssim_skimage(gt, pred, data_range=data_range)
def plot_results(gt, cnn, prms, label, folder=None):
if folder is None:
folder = os.path.join(ndtomopath(), 'examples', 'results')
mae_vals = [
mae(gt, cnn),
mae(gt, prms)
]
ssim_vals = [
ssim(gt, cnn),
ssim(gt, prms)
]
mse_vals = [
mse(gt, cnn),
mse(gt, prms)
]
rmse_vals = [
rmse(gt, cnn),
rmse(gt, prms)
]
psnr_vals = [
psnr(gt, cnn),
psnr(gt, prms)
]
# Labels
methods = ['PeakFitCNN', 'prms-only']
metrics = ['MAE', 'SSIM', 'MSE', 'RMSE', 'PSNR']
all_metrics = [mae_vals, ssim_vals, mse_vals, rmse_vals, psnr_vals]
# Plot each metric in a separate figure
for i, (metric_name, values) in enumerate(zip(metrics, all_metrics)):
plt.figure(figsize=(6, 5))
bars = plt.bar(methods, values)
# Annotate bars with values
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2, height * 1.01, f'{height:.6f}',
ha='center', va='bottom', fontsize=10)
plt.ylabel(metric_name)
plt.title(f'{label} {metric_name} Comparison')
plt.grid(axis='y', linestyle='--', alpha=0.6)
plt.tight_layout()
plt.savefig(os.path.join(folder, f'{label}_{metric_name}_real_space.png'), dpi=300)
plt.show()
[20]:
gt = peak_area * msk
cnn = cnn_peak1_area * msk
prms = prms_peak1_area * msk
print("CNN MAE:", mae(gt, cnn))
print("PRMS MAE:", mae(gt, prms))
print("CNN SSIM:", ssim(gt, cnn))
print("PRMS SSIM:", ssim(gt, prms))
print("CNN MSE:", mse(gt, cnn))
print("PRMS MSE:", mse(gt, prms))
print("CNN RMSE:", rmse(gt, cnn))
print("PRMS RMSE:", rmse(gt, prms))
print("CNN PSNR:", psnr(gt, cnn))
print("PRMS PSNR:", psnr(gt, prms))
plot_results(gt, cnn, prms, label='Area')
CNN MAE: 0.012211051166407118
PRMS MAE: 0.029221594766366446
CNN SSIM: 0.9420320056226766
PRMS SSIM: 0.7525158257218323
CNN MSE: 0.00043586489682430313
PRMS MSE: 0.001944896965449163
CNN RMSE: 0.02087737763284228
PRMS RMSE: 0.04410098599180253
CNN PSNR: 35.5446813228951
PRMS PSNR: 29.049234273066435
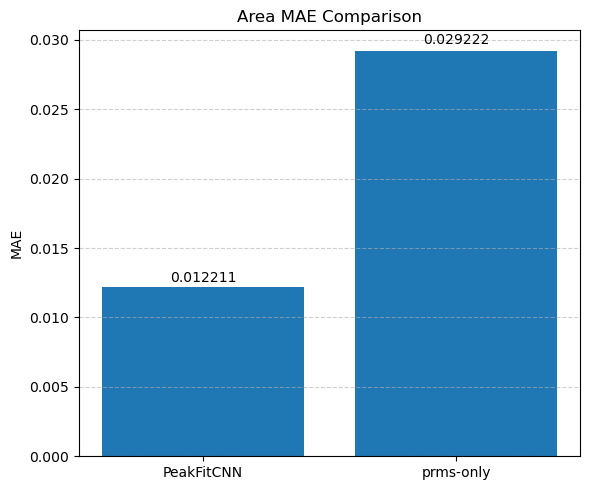
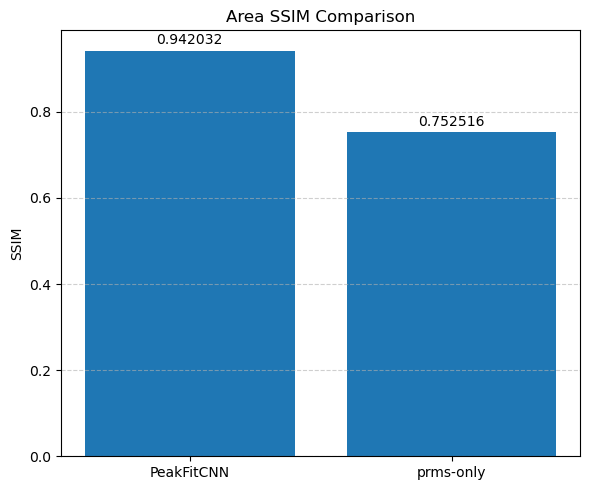
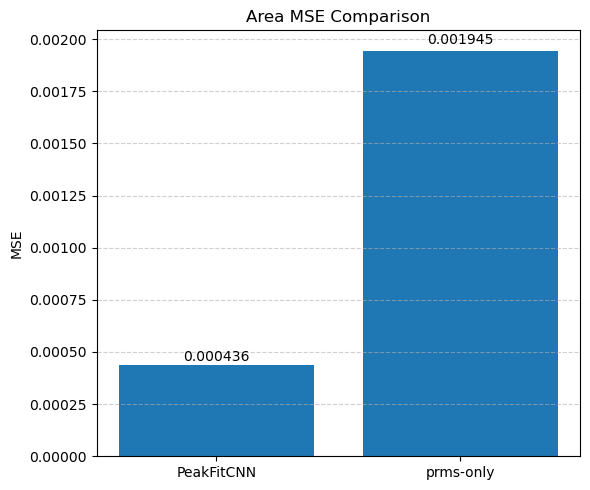
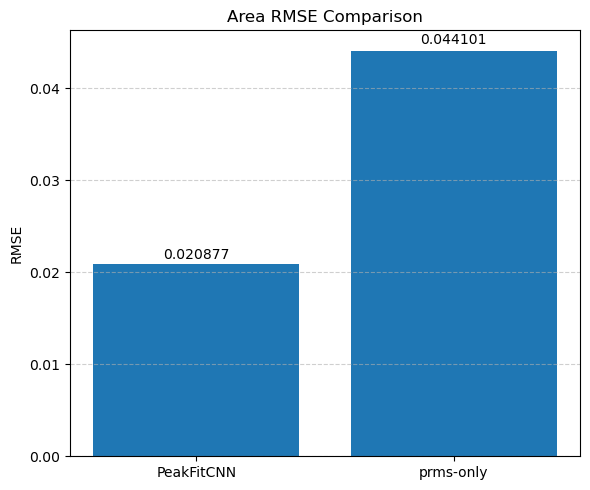
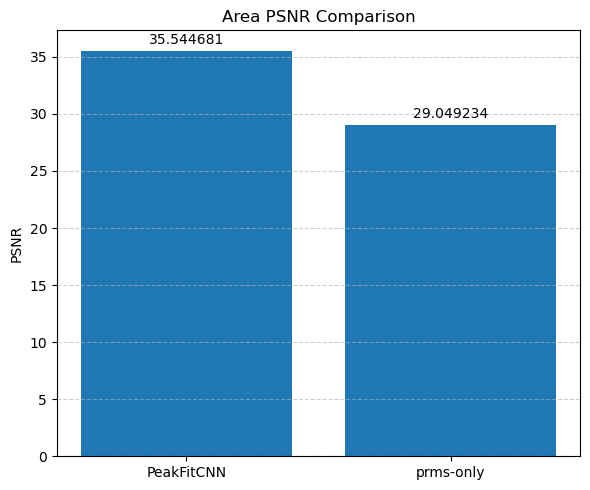
[21]:
gt = peak_position * msk
cnn = cnn_peak1_pos * msk
prms = prms_peak1_pos * msk
print("CNN MAE:", mae(gt, cnn))
print("PRMS MAE:", mae(gt, prms))
print("CNN SSIM:", ssim(gt, cnn))
print("PRMS SSIM:", ssim(gt, prms))
print("CNN MSE:", mse(gt, cnn))
print("PRMS MSE:", mse(gt, prms))
print("CNN RMSE:", rmse(gt, cnn))
print("PRMS RMSE:", rmse(gt, prms))
print("CNN PSNR:", psnr(gt, cnn))
print("PRMS PSNR:", psnr(gt, prms))
plot_results(gt, cnn, prms, label='Position')
CNN MAE: 0.01088030103507601
PRMS MAE: 0.02085275130415404
CNN SSIM: 0.9843197029471591
PRMS SSIM: 0.9455460579504422
CNN MSE: 0.00036186108168220917
PRMS MSE: 0.0015045924796861603
CNN RMSE: 0.01902264654779164
PRMS RMSE: 0.03878907680889248
CNN PSNR: 43.95700632381245
PRMS PSNR: 37.76823622658645
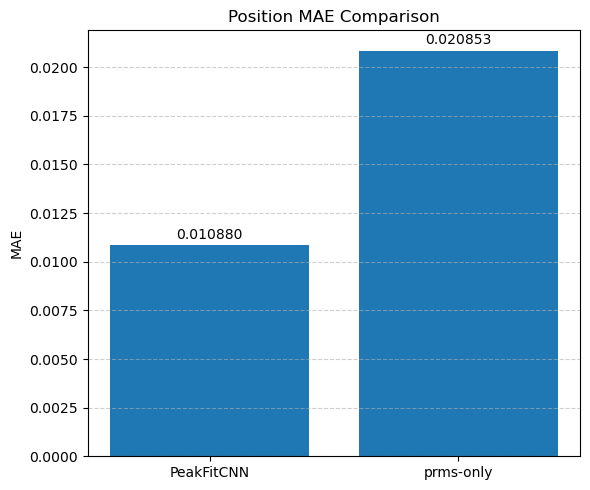
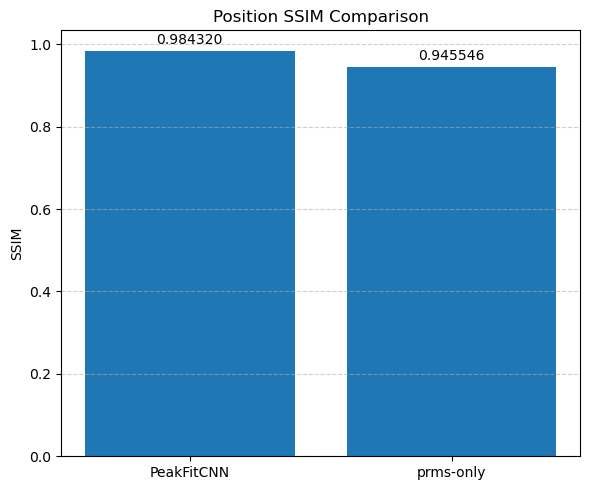
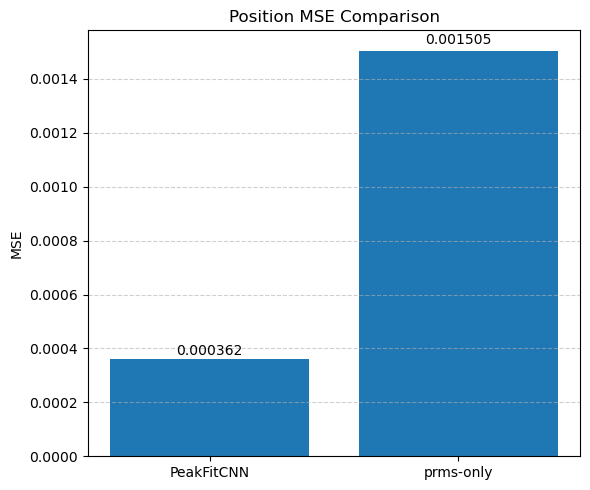
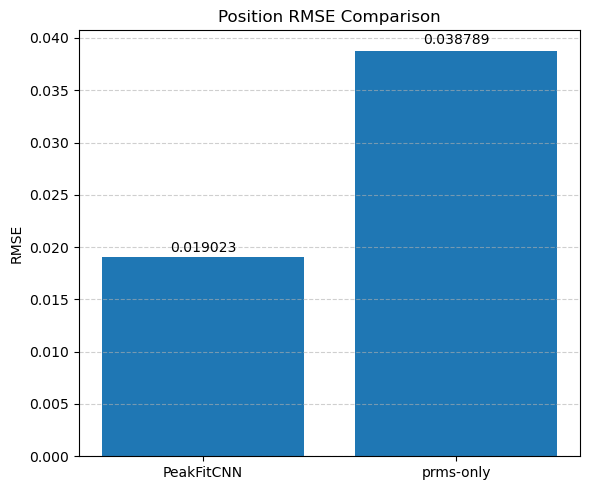
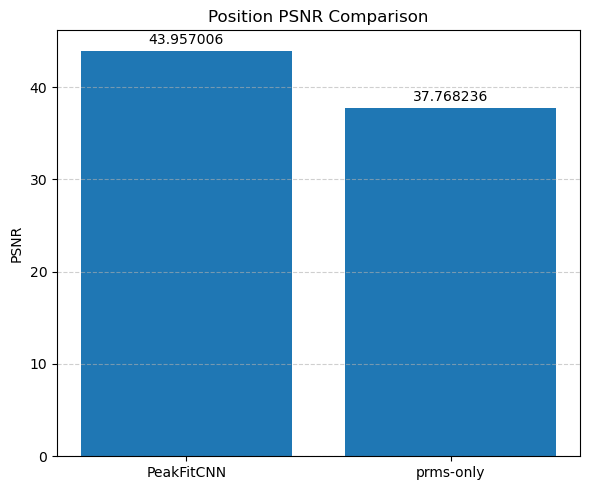
[22]:
gt = peak_fwhm * msk
cnn = cnn_peak1_fwhm * msk
prms = prms_peak1_fwhm * msk
print("CNN MAE:", mae(gt, cnn))
print("PRMS MAE:", mae(gt, prms))
print("CNN SSIM:", ssim(gt, cnn))
print("PRMS SSIM:", ssim(gt, prms))
print("CNN MSE:", mse(gt, cnn))
print("PRMS MSE:", mse(gt, prms))
print("CNN RMSE:", rmse(gt, cnn))
print("PRMS RMSE:", rmse(gt, prms))
print("CNN PSNR:", psnr(gt, cnn))
print("PRMS PSNR:", psnr(gt, prms))
plot_results(gt, cnn, prms, label='FWHM')
CNN MAE: 0.005207019302338179
PRMS MAE: 0.01294882830216101
CNN SSIM: 0.8893653381763068
PRMS SSIM: 0.6277228080220981
CNN MSE: 7.661597138441027e-05
PRMS MSE: 0.00035357032509610525
CNN RMSE: 0.00875305497437382
PRMS RMSE: 0.018803465773524444
CNN PSNR: 33.19800670450243
PRMS PSNR: 26.556441748098635
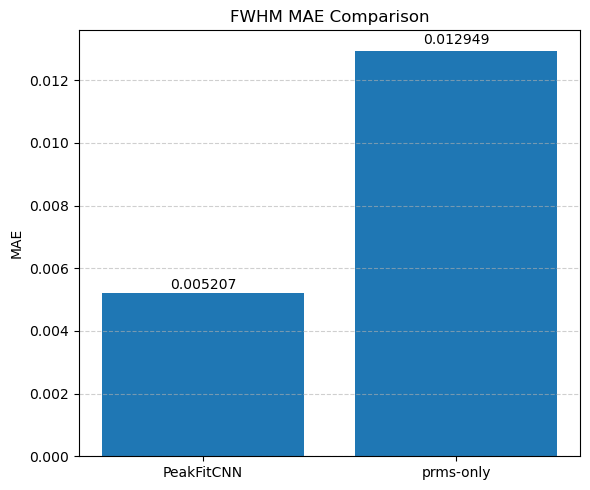
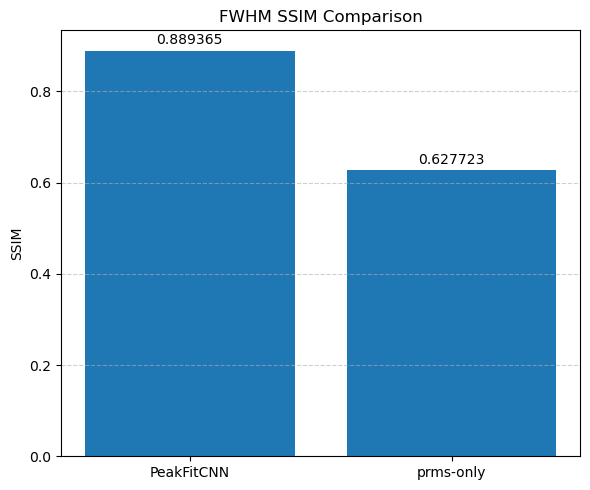
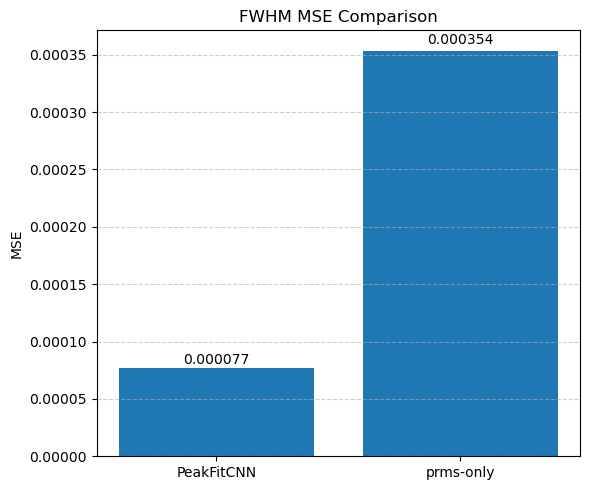
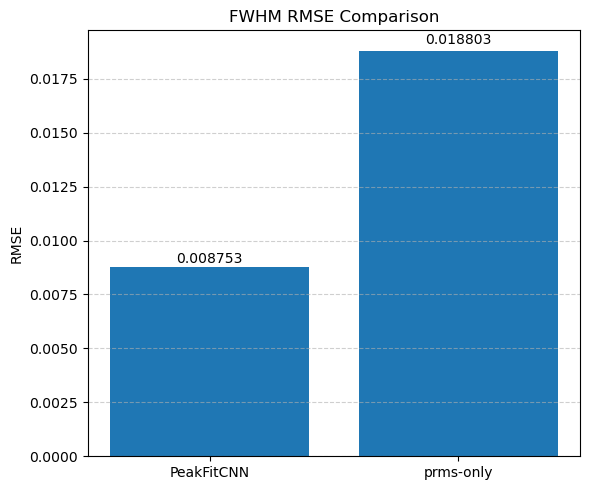
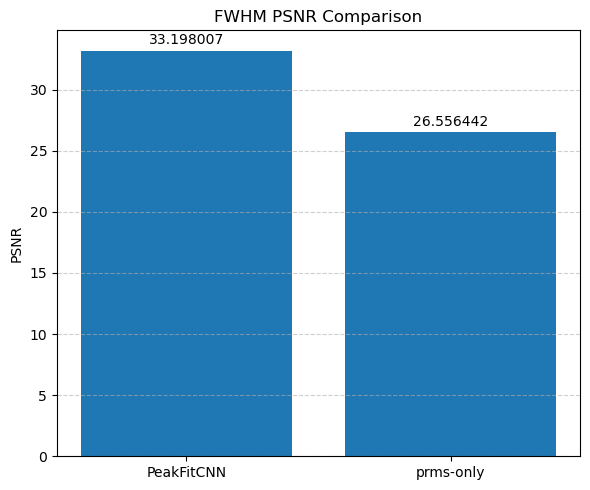
[23]:
gt = peak_slope * msk
cnn = cnn_slope * msk
prms = prms_slope * msk
print("CNN MAE:", mae(gt, cnn))
print("PRMS MAE:", mae(gt, prms))
print("CNN SSIM:", ssim(gt, cnn))
print("PRMS SSIM:", ssim(gt, prms))
print("CNN MSE:", mse(gt, cnn))
print("PRMS MSE:", mse(gt, prms))
print("CNN RMSE:", rmse(gt, cnn))
print("PRMS RMSE:", rmse(gt, prms))
print("CNN PSNR:", psnr(gt, cnn))
print("PRMS PSNR:", psnr(gt, prms))
plot_results(gt, cnn, prms, label='Slope')
CNN MAE: 0.00013868057227257234
PRMS MAE: 0.0010409618255452634
CNN SSIM: 0.8950820279409483
PRMS SSIM: 0.21679186462020572
CNN MSE: 4.72943892986441e-07
PRMS MSE: 2.354981402212602e-06
CNN RMSE: 0.0006877091630816337
PRMS RMSE: 0.0015345948658237463
CNN PSNR: 31.210703954470624
PRMS PSNR: 24.238925355812142
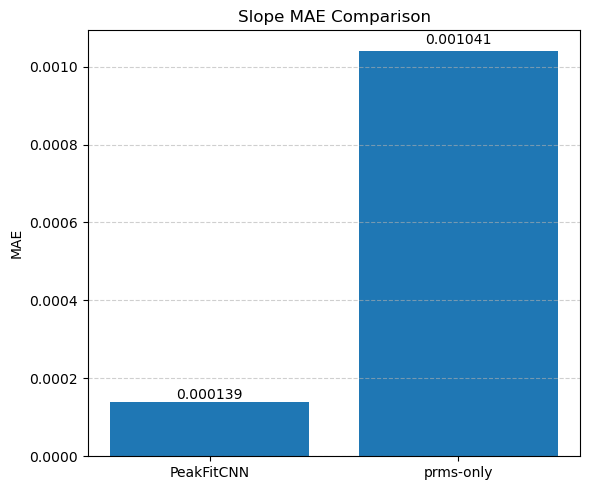
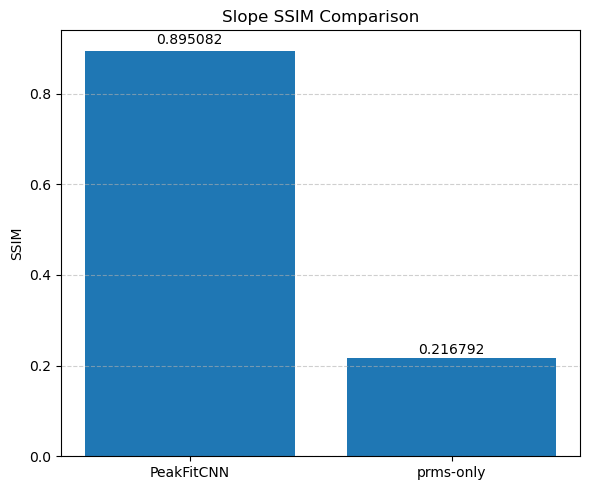
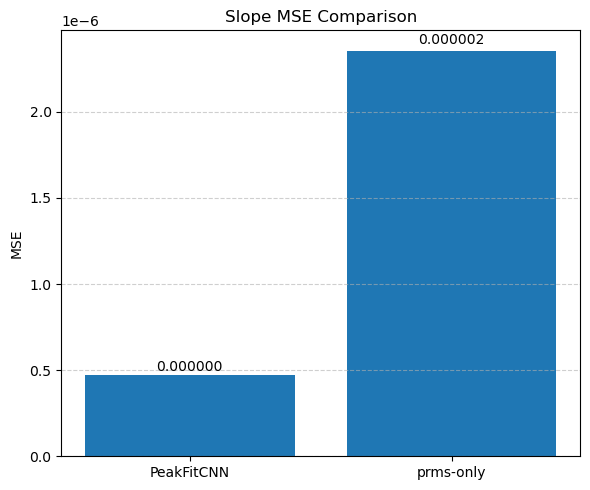
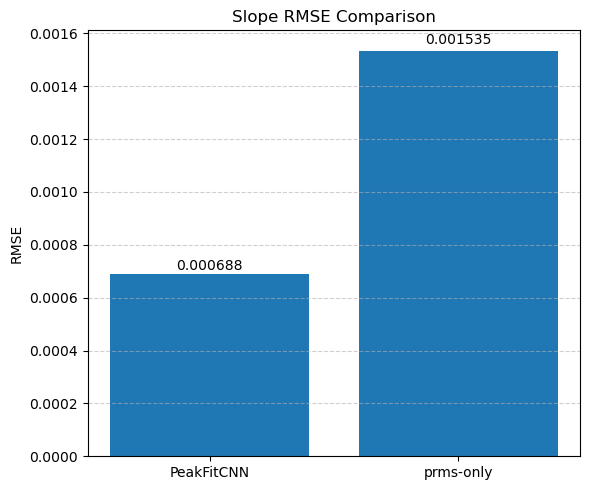
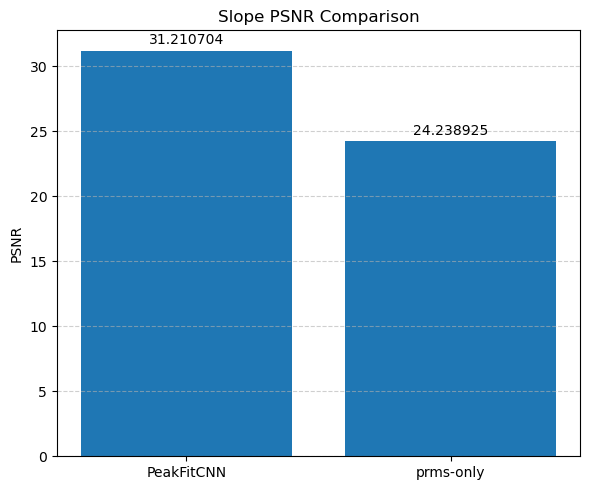
[24]:
gt = peak_intercept * msk
cnn = cnn_intercept * msk
prms = prms_intercept * msk
print("CNN MAE:", mae(gt, cnn))
print("PRMS MAE:", mae(gt, prms))
print("CNN SSIM:", ssim(gt, cnn))
print("PRMS SSIM:", ssim(gt, prms))
print("CNN MSE:", mse(gt, cnn))
print("PRMS MSE:", mse(gt, prms))
print("CNN RMSE:", rmse(gt, cnn))
print("PRMS RMSE:", rmse(gt, prms))
print("CNN PSNR:", psnr(gt, cnn))
print("PRMS PSNR:", psnr(gt, prms))
plot_results(gt, cnn, prms, label='Intercept')
CNN MAE: 0.0018089310351023344
PRMS MAE: 0.0053836516431930645
CNN SSIM: 0.923784755568675
PRMS SSIM: 0.6528880802626799
CNN MSE: 1.1417305950289654e-05
PRMS MSE: 6.624434566300505e-05
CNN RMSE: 0.003378950421401541
PRMS RMSE: 0.008139062947477741
CNN PSNR: 37.3831637831615
PRMS PSNR: 29.7473120269228
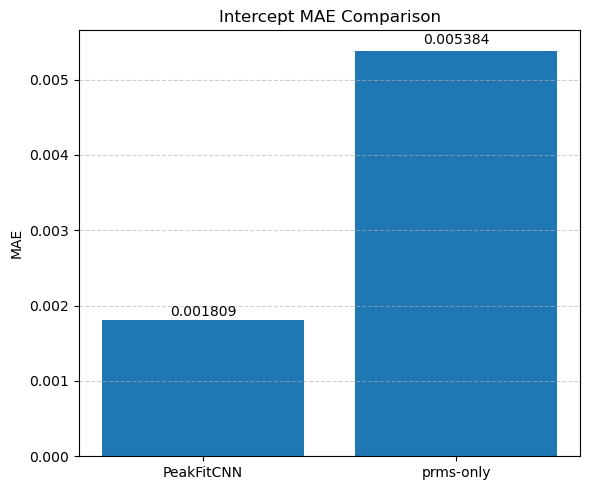
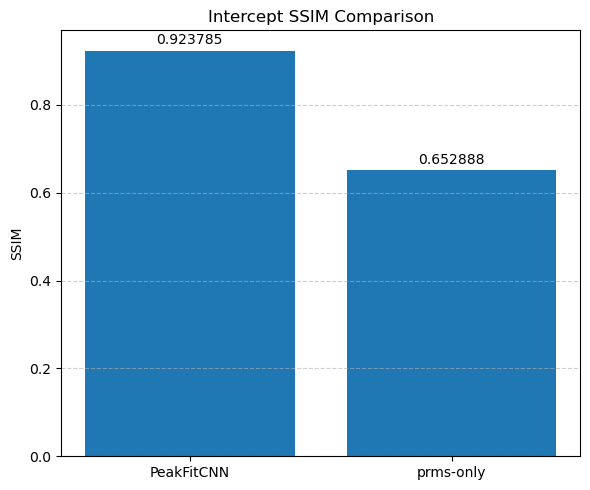
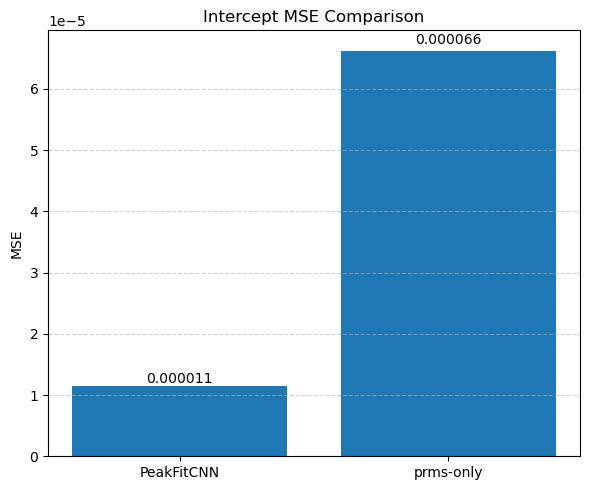
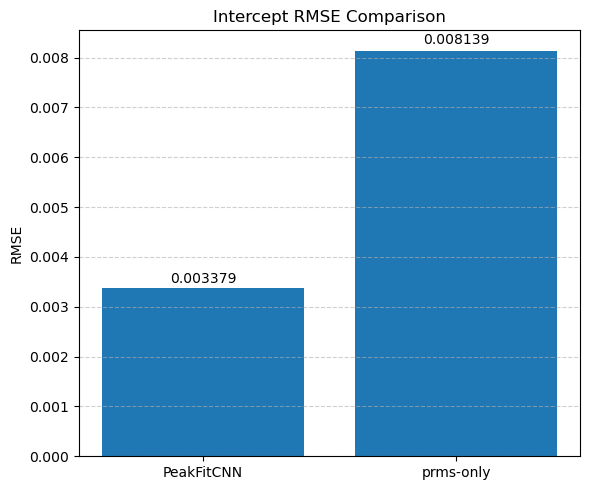
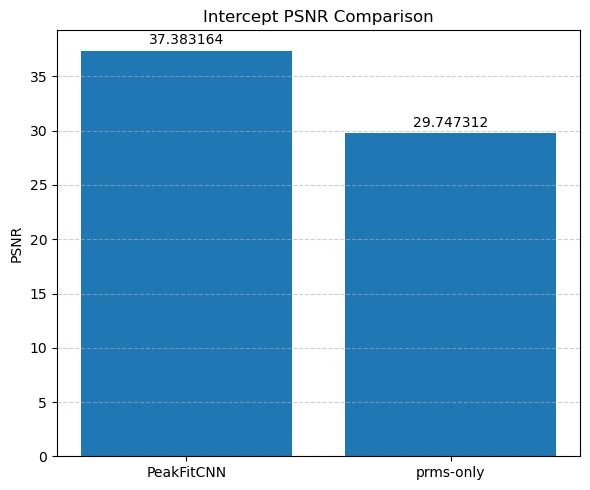
✅ Quantitative Comparison of CNN vs. Conventional Fitting
We evaluated the performance of the PeakFitCNN model against the conventional fitting approach using five standard metrics: MAE, MSE, RMSE, SSIM, and PSNR.
Across all parameter maps (area, position, FWHM, slope, and intercept), the CNN-based predictions consistently showed:
Lower MAE, MSE, and RMSE compared to the conventional approach, indicating smaller average and squared errors.
Higher SSIM and PSNR, suggesting better structural fidelity and improved signal-to-noise characteristics.
These results confirm that the PeakFitCNN model produces more accurate and visually coherent parameter maps than the conventional fitting method.
Summary and Final Remarks
In this notebook, we compared two distinct strategies for hyperspectral peak fitting in synthetic XRD-CT datasets:
📌 Conventional Approach
Uses explicit, per-parameter 2D maps to define each peak and background component.
These parameter maps are trained directly to minimize spectral reconstruction error.
While effective, this approach does not leverage spatial or spectral context beyond local filtering.
📌 PeakFitCNN (Self-Supervised CNN)
Uses a downsampled hyperspectral input and learns to output full-resolution, denoised parameter maps.
Trained using a self-supervised loss based on spectral reconstruction, requiring no labelled parameter maps.
Combines denoising, resolution enhancement, and peak decomposition in a single, end-to-end architecture.
🧪 Results and Observations
Both methods successfully reconstructed the peak parameters, even in the presence of Poisson noise.
PeakFitCNN showed improved spatial coherence, and slightly lower noise levels in the parameter maps.
The CNN was also able to generalize from lower-resolution inputs, demonstrating its potential for super-resolution peak fitting in real experimental contexts.
📈 Future Directions
Extend to multi-peak or asymmetric peak fitting models (e.g. Pseudo-Voigt).
Train PeakFitCNN on experimental data using self-supervised or semi-supervised frameworks.
Integrate physical priors or constraints (e.g. non-negativity, continuity) directly into the CNN architecture.
This approach demonstrates the feasibility of combining physical modelling with modern deep learning techniques to enhance chemical imaging workflows in XRD-CT and beyond.